AWS Batch – The most important information
AWS Batch is a fully-managed AWS service that enables developers, scientists, and engineers to quickly and efficiently run hundreds of thousands of batch computing jobs on AWS. It dynamically provisions the optimal quantity and compute resources based on the volume and specific resource requirements of the batch jobs submitted. With AWS Batch, there is no need to install and manage batch computing software or server clusters that you use to run your jobs, allowing you to focus on analyzing results and solving problems at any scale.
In this article, we’ll cover the most important information about AWS Batch, including its features, jobs, and schedulers. Let’s get started!
What is AWS Batch?
AWS Batch dynamically provisions and executes your batch computing workloads across the full range of AWS compute services and features, such as AWS Fargate, On-demand EC2, Spot EC2 instances, and Amazon EKS.
AWS Batch organizes its work into four components:
- Jobs – the unit of work submitted to Batch, whether implemented as a shell script, executable, or Docker container image.
- Job Definition – describes how your work is executed, including the CPU and memory requirements and IAM role that provides access to other AWS services.
- Job Queues – listing of work to be completed by your Jobs. You can leverage multiple queues with different priority levels.
- Compute Environment – the compute resources that run your Jobs. Environments can be configured to be managed by AWS or on your own, as well as several types of instances on which Jobs will run. You can also allow AWS to select the right instance type.
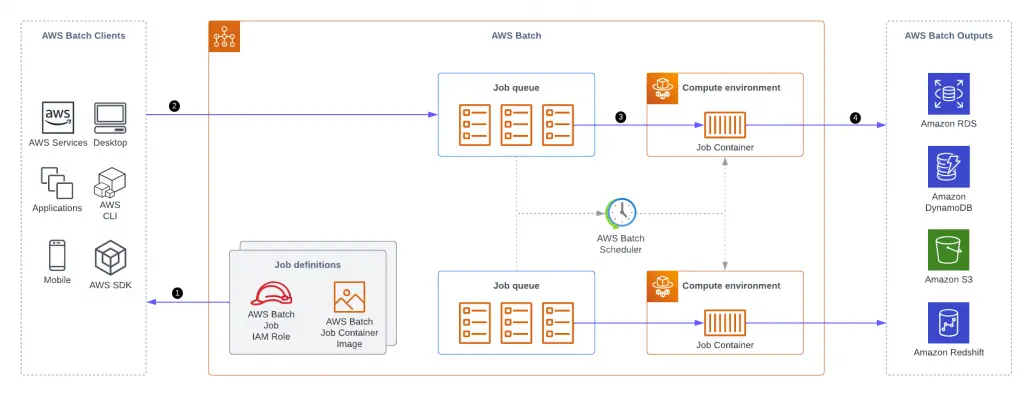
Batch job queues are mapped to one or more compute environments of the following types:
- MANAGED – the compute environment where AWS manages the autoscaling of compute resources
- UNMANAGED – a compute environment where you manage your own compute resources
Features
- Compute resources run only when jobs are executed, taking advantage of per-second billing. You can also lower your costs by using spot instances.
- It’s possible to configure how many retries you’d like for any job.
- It offers queues where you send the jobs. Each queue could be configured with a certain priority so you can configure which jobs will run first. You can also have queues that use better resources to speed up the process.
- It supports Docker containers so that you can focus only on your code.
Batch Job
A Batch job is a computing task that runs until the task is completed successfully or fails. A Batch job is not a continuous task, it has a start and an end.
AWS Batch allows you to run hundreds of thousands of batch jobs on AWS.
The major benefit of Batch is cost optimization because we no longer have to focus on infrastructure management activities.
AWS Batch provisions the required capacity based on the length of the batch queue, where you send tasks for execution.
Check the “Boto3 Batch – Complete Tutorial” article to see an example of running a Batch task that imports records from a file uploaded to the S3 bucket into a DynamoDB table.
Batch Job states
Here’s a list of AWS Batch jobs states:
| Job State | Description |
|---|---|
| SUBMITTED | The job has been placed in the queue |
| PENDING | The job is waiting for execution |
| RUNNABLE | The job has been evaluated by the scheduler and is ready to run |
| STARTING | The job is in the process of being scheduled to a compute resource |
| RUNNING | The job is currently running |
| SUCCEEDED | The job finished with exit code 0 |
| FAILED | The job exited with a non-zero exit code, canceled or terminated |
Job definition
The Batch Job definition is a simple JSON document describing how the Docker container executing the job should be run. Some of the most useful parameters of the job definition include Docker image, vCPU/memory resources, the command to run in the container, data volumes mapping, etc.
Most Batch job definitions’ parameters can be overridden in the runtime.
AWS Batch Scheduler
The Batch Scheduler evaluates when, where, and how to run jobs submitted to a job queue. Jobs run in the order they are introduced as long as all dependencies on other jobs have been met.
AWS Batch vs. Lambda
AWS Batch and AWS Lambda look very similar, but they have some significant differences:
| AWS Lambda | AWS Batch | |
|---|---|---|
| Execution time | 15 mins | No limit |
| Runtime | Limited / Can be customized | Unlimited (must be a Docker image) |
| Temporary storage | 10 GB | EBS / EC2 instance store limits |
| Scalability | Serverless (extremely fast) | Fargate / EC2 Auto Scaling (slower) |
Free hands-on AWS workshops
To get free hands-on experience with AWS Batch, we recommend you the following AWS Batch workshops:
- Running batch workloads on Amazon EKS with AWS Batch
- Fair-share scheduling on AWS Batch
- Run containerized workloads on AWS Batch
- Running GROMACS on AWS Batch
- GROMACS on AWS Batch
- Nextflow on AWS Batch
