Amazon Aurora is a MySQL and PostgreSQL-compatible cloud-native database (based on the open-source MySQL and PostgreSQL code) that offers high performance, extreme scalability, and availability at a fraction of the cost, and it is an invaluable addition to the Amazon Relational Database Service (RDS).
Amazon Aurora has so many amazing features to offer! For example, its storage scales up to 128 TB of data by 10 GB increments when needed, unused storage (after delete operations) is returned to AWS, and you don’t have to pay for it. Aurora Serverless will free you from DB operational efforts, and its integration with AWS DevOps Guru will help you fix your database problems even if you didn’t know they existed. Finally, Aurora Global Database can help you to span your database data across multiple geographical regions with no effort from your side.
This post covers the most important Amazon Aurora features and links to the most important in-depth materials and hands-on labs. Let’s get started!
As soon as Amazon Aurora is a cloud-native database built on top of MySQL and PostgreSQL open-source code, your PostgreSQL or MySQL DB application’s clients will work with it without any change.
Amazon Aurora storage automatically grows in increments of 10 GB up to 128 TB as you write more data to the DB.
While using Amazon Aurora, DevOps or CloudOps engineers now don’t have to worry about the DB’s disks, they will grow automatically over time.
Performance and scalability
AWS states that Amazon Aurora has 5x throughput of standard MySQL and 3x of standard PostgreSQL DBs. AWS Aurora decoupled compute and storage for cost optimization. It scales up to 15 replicas.
Availability and durability
Each Amazon Aurora cluster stores six copies of your data across three Availability Zones while you’re paying only for one copy (even if you’re using only one Aurora instance in the cluster). The DB needs 4 out of 6 copies of your data to perform write operations (if one AZ is down, you’re OK) and 3 out of 6 copies for reads.
Aurora offers higher availability and better durability than other RDS databases due to its unique storage model and ability to perform continuous backups and restore with a very low RPO (recovery point objective).
Additional important features
- Automatic, continuous incremental backups with point-in-time recovery (PITR)
- Fault-tolerant, self-healing autoscaling storage
- Automatic failover
- Global database for cross-region disaster recovery
- Security
- Network isolation
- Encryption
- Multiple secure authentication mechanisms and audit controls
- Advanced monitoring
- Automated patching with zero downtime
- Automated backups
Aurora MySQL and Aurora PostgreSQL are HA-native by design and have an instantaneous failover to another Availability Zone (AZ) during the AZ outage.
Aurora is ~20% more expensive than RDS, but it is worth it, as it provides scalability and many exciting features reducing Ops engineering work!
Aurora Cluster Architecture
Under the hood, the Aurora DB cluster shares the same storage volume between writer and read replicas. It replicates your data without impacting database performance, enables fast local reads with low latency in each region, and provides disaster recovery from region-wide outages. For in-depth information about purpose-built Amazon Aurora storage, check out the following video:
Aurora has a self-healing mechanism using peer-to-peer replication in the backend and striped on hundreds (100s) of volumes.
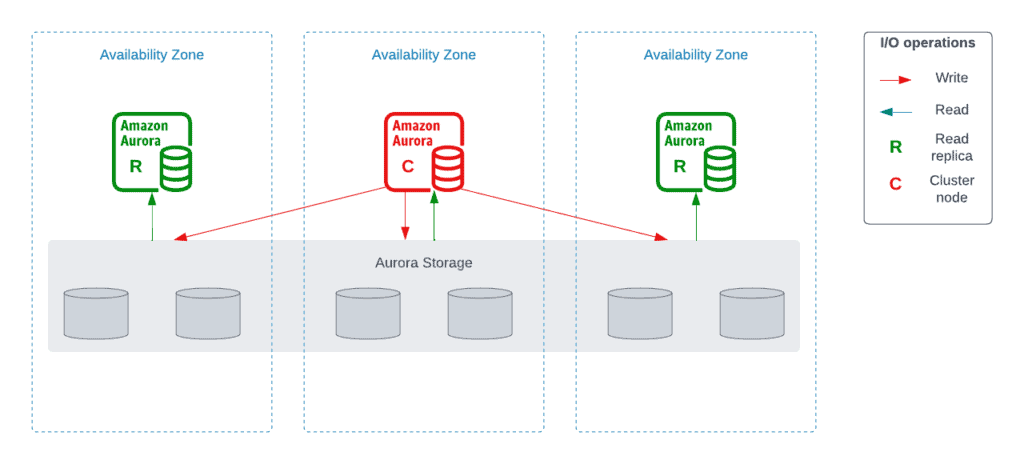
One primary (or cluster) instance in one of the AZs of the DB takes writes. In addition, you may have up to 15 read replicas to serve reads. If the primary instance fails, automated failover happens to one of the other Aurora replicas in less than 30 seconds on average.
Such a unique storage architecture of Amazon Aurora provides you with fast database cloning and point-in-time recovery.
Read replicas rely on storage Cross Region Replication (CRR).
Connection endpoints
As a DB user, you have a Cluster Endpoint that points to the cluster instance of the DB (read/write operations). Reader Endpoint provides connection load balancing between all read replicas of the cluster (launched in Auto Scaling mode). Optionally, you can have a Custom Endpoint pointing to bigger Aurora nodes, for example, for SQL analytical queries.

Aurora Serverless
Aurora Serverless allows you to instantiate a database and automatically scale its write and read replicas based on actual usage. Aurora Serverless is a great option for infrequent, intermittent, or unpredictable workloads or if you don’t want to do any capacity planning.
You’re paying per second for each DB instance spun up for you by AWS. When DB is not used, all DB instances are automatically tiered down. As soon as the new connection comes, it might take a couple of seconds to spin up a writer instance for you and process the request. All these become possible because of decoupling Aurora compute resources from the DB storage system.
Note: you have to choose a supported MySQL or PostgreSQL database engine version to use Aurora Serverless.
Aurora Multi-Master
Aurora Multi-Master creates multiple read-write instances in an Aurora database across multiple Availability Zones, enabling uptime-sensitive applications to achieve continuous write availability through instance failure.
You can use the Aurora Multi-Master setup option if you want an immediate failover for a write node (HA). In that case, all nodes of the Aurora cluster can do reads and writes, and there’s no need for promoting a read replica as a new master in case of disaster.
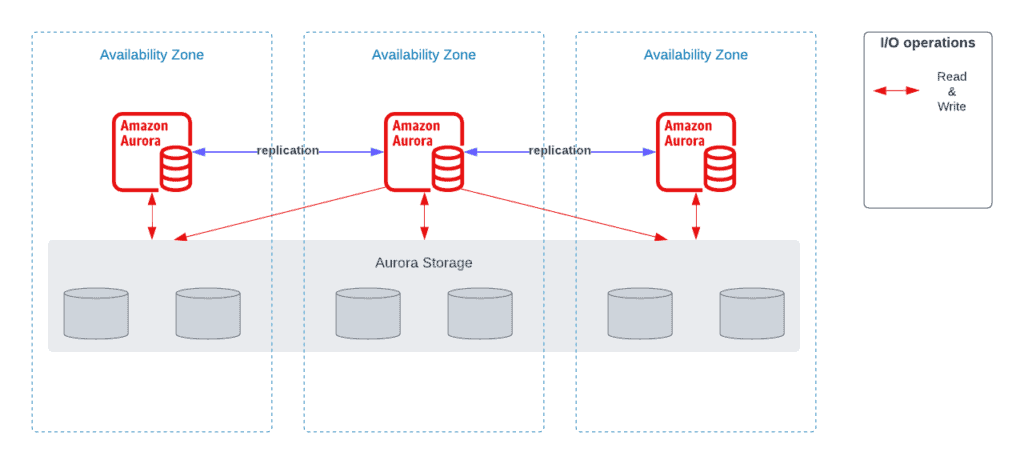
For more in-depth information about Aurora Multi-Master, I strongly suggest the following video (demo included):
Aurora Global Database
Aurora Global Database is designed for globally distributed applications, allowing a single Amazon Aurora database to span multiple AWS regions, which is great for disaster recovery.
With global database clusters, you have one primary AWS region where all reads and writes are happening. And you can have up to 5 secondary read-only regions (replication lag is less than 1 second) having up to 16 read replicas per region.
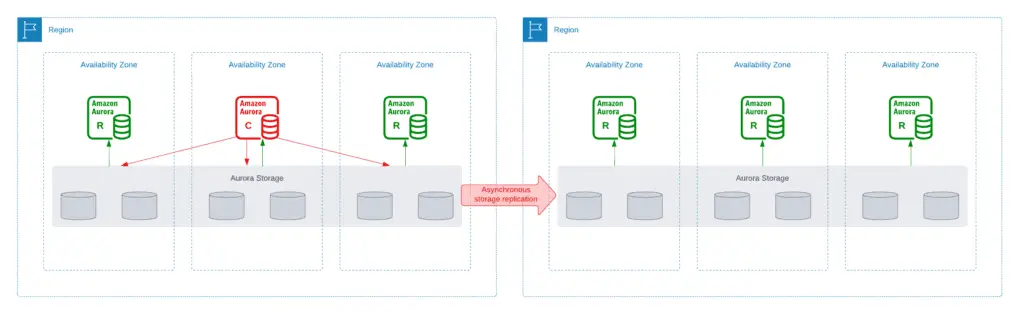
Such a configuration allows you to decrease latency for the read replicas worldwide. Promoting another region in case of disaster (RTO) takes less than a minute.
Typical cross-region replication takes less than one second.
For more in-depth information about Aurora Global DB, watch the following video (demo included):
Note: you have to choose a supported MySQL or PostgreSQL database engine version to use Aurora Global DB.
Important integrations
RDS Proxy
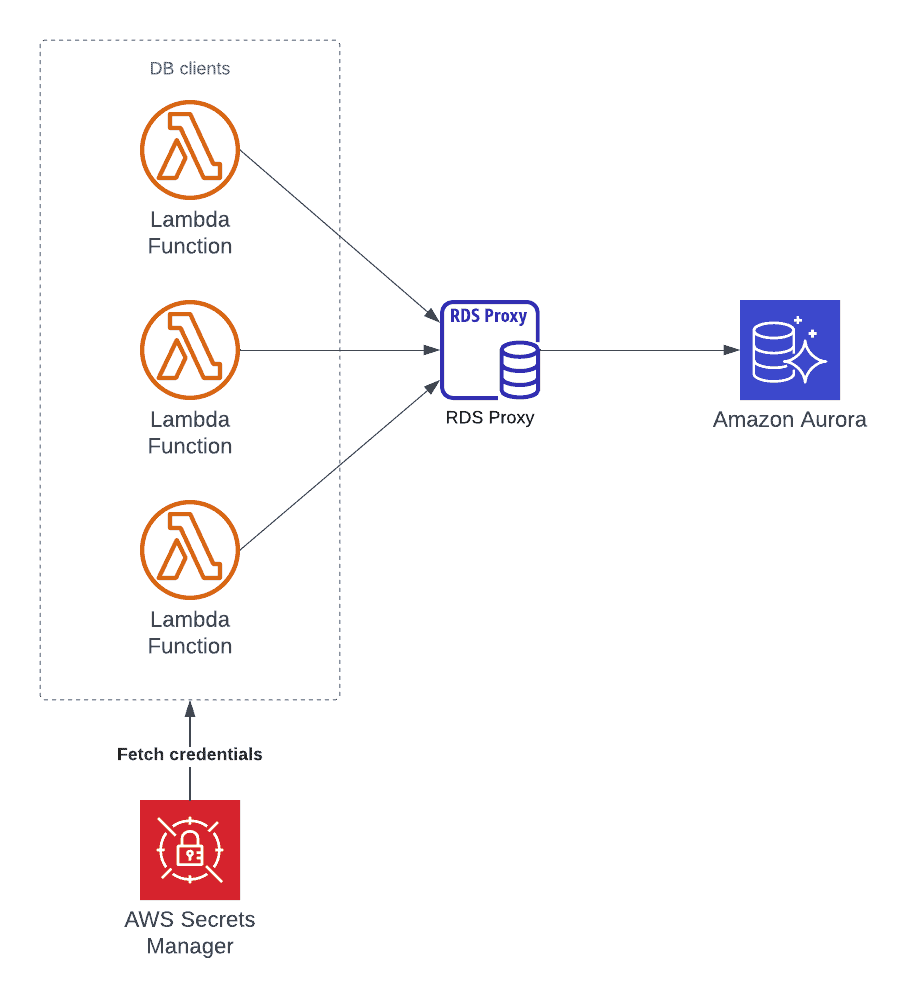
RDS Proxy is a fully managed, highly available database proxy that improves application scalability, resiliency, and security. Using an RDS proxy in front of any RDS database (including Aurora) for Serverless workloads is highly recommended. For example, consider RDS Proxy if you need to interact with Aurora using Lambda functions.

Secrets Manager
Aurora RDS Proxy integration will automatically use Secrets Manager for storing Aurora DB credentials in Secrets Manager. Even if you’re not using an RDS proxy, it is highly recommended to manage master user credentials in Secrets Manager. RDS can generate a password for you and manage it throughout its lifecycle.
Here’s a typical architecture for accessing the Aurora database clusters using credentials stored in Secrets Manager:
Aurora Machine Learning
Aurora has an optimized and secure integration with two Machine Learning AWS services to enable you with ML-based predictions via SQL query interface:
- Amazon SageMaker (ML models)
- Amazon Comprehend (sentiment analysis)
You don’t have to be an ML expert to make product recommendations, fraud detection, sentiment analysis, etc.
Amazon DevOps Guru for RDS
Amazon DevOps Guru for RDS is a Machine Learning (ML)-powered capability for Amazon RDS that automatically detects and diagnoses database performance and operational issues with your relational database workloads, enabling you to resolve bottlenecks in minutes.

GuardDuty RDS protection
The GuardDuty RDS protection feature automatically analyzes connection and logging-in information to find suspicious attempts to log into your database.
Hands-on Aurora Database Lab
If you’re looking for hands-on experience using Aurora in AWS, we strongly suggest you check the “Amazon Aurora Labs for PostgreSQL” workshop provided by AWS.
Summary
There are many benefits of using Amazon Aurora. First, it provides a cost-effective way to store large amounts of data and reduces operational overhead on DB management. Amazon Aurora has higher durability, reliability, and performance than open-source databases. Amazon Aurora is also easy to use, which makes it a great choice for businesses of all sizes.
