Amazon EMR (Amazon Elastic MapReduce) is a web service that enables you to quickly and easily create and run clusters of Amazon Elastic Compute Cloud (EC2) instances for processing large amounts of data by running MapReduce jobs. Amazon EMR uses Hadoop, an open-source framework, to manage and process data.
In this article, we’ll provide the most important information you need to know about Amazon Elastic MapReduce (EMR) service. Let’s get started!
AWS EMR is a managed Hadoop framework to process and analyze vast amounts of data using hundreds of EC2 instances. To launch a Hadoop cluster, you need to specify how many EC2 instances your cluster should consist of, cluster EC2 instances types, and what software to install.
You can manage EMR clusters using the following options:
- CloudFormation stacks
- AWS CDK
- Terraform
- Direct API calls using SDKs
- AWS CLI
AWS EMR supports the following BigData frameworks: Apache Spark, HBase, Presto, and Hadoop.
To develop a code that processes data in your cluster, you can use EMR Notebooks.
Benefits
Some benefits of Amazon EMR include:
- Reduced Costs: Amazon EMR helps reduce costs by allowing you to use your on-premises hardware for compute and storage. You can also use Spot Instances for cluster Task nodes to reduce costs even further.
- Increased Efficiency: Amazon EMR helps you be more efficient with your data by allowing you to easily and quickly analyze it using big data tools and services.
- Scalability: Amazon EMR is scalable, so you can grow your Hadoop deployment as needed.
- Lowered operational complexity: The ability to process and analyze vast amounts of data quickly and easily.
Features
The primary feature of AWS EMR is to take care of all provisioning and configuration of Apache Spark, Apache HBase, Apache Hive, Presto, Flink, and other BigData frameworks within the single cluster, which you use to process and analyze data in your cloud data warehousing infrastructure.
Additional features of AWS EMR include:
- Rapid provisioning of computing capacity for MapReduce tasks
- Flexible configuration allowing customization of clusters
- Integrated management and monitoring from a web console
- Ability to run tasks on a schedule or in response to events
- AWS Auto Scaling integrated with Spot instances
- Amazon EMR Serverless for cost-effective processing variable workloads in dev and test environments
- Native integration with storage and BigData AWS services
Use cases
Use cases for Amazon EMR include:
- Data processing and transformations – Amazon EMR can be used for transforming and loading data into Amazon Simple Storage Service (Amazon S3) for analysis or ETL (extract, transform, load) data operations
- Machine Learning – you can train Machine Learning models using Apache Spark in EMR and deploy them in SageMaker
- BigData analytics – you can use Amazon EMR for analyzing big datasets using Hadoop and other open-source analytics tools, testing and deploying new big data processing applications and services
- Real-time streaming – you can analyze data coming from Apache Kafka, Amazon Kinesis, or other streaming data sources in real-time using Apache Spark Streaming and Flink
- Data and web indexing – in combination with the Amazon OpenSearch cluster, Amazon EMR can help with the processing of any data indexing tasks
- Log Analysis
- Financial analysis in Amazon Web Services cloud
- Genomic data analysis in AWS cloud
Pricing
Amazon EMR pricing model is the same as Amazon EC2 pricing model: you pay only for the EC2 instances you use in the cluster.
There are several compute purchasing options available:
- On-demand: use on-demand instances for reliable, predictable workloads
- Reserved: you can save AWS EMR costs by purchasing reserved instances for Master and Core nodes
- Spot instances: use cheap EC2 instances that can be terminated at any time for EMR Task nodes
Cluster architecture
EMR clusters consist of EC2 instances. Each instance plays a certain role within the provisioned cluster:
- Master node – A master node is the foundation of a cluster, responsible for running software components that direct data distribution and tasks between other nodes. It keeps close watch over task statuses and assesses the system’s overall health – even single-node clusters depend on one master node to operate efficiently.
- Core nodes – A node with software components that run tasks and store data in your cluster’s Hadoop Distributed File System (HDFS). Multi-node clusters have at least one core node.
- Task nodes – A node with software components that only runs tasks and does not store data in HDFS. Task nodes are optional. And they are a perfect choice for the Spot instances option.
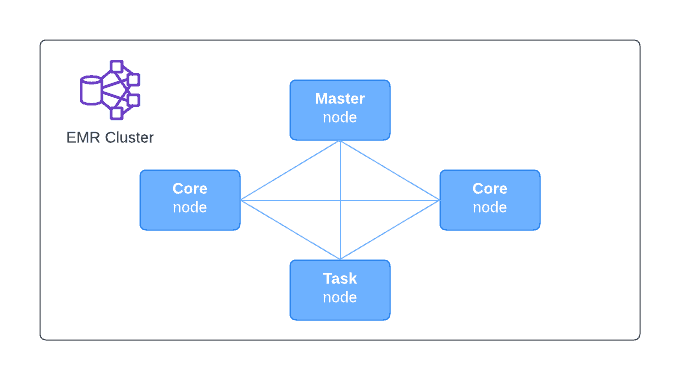
Core and Task nodes allow you to scale your cluster’s storage and compute capacity independently. Add more Core nodes to increase storage and compute capacity simultaneously, or add only task nodes to increase compute capacity only.
Amazon EMR allows simplifying cluster resource management for you.
Amazon EMR storage options
There are three storage options available for each EMR cluster:
- Hadoop Distributed File System (HDFS): a distributed, scalable, and portable file system for Hadoop
- EMR File System (EMRFS): an implementation of the Hadoop file system used for reading and writing regular files from Amazon EMR directly to Amazon S3
- The local file system of EC2 nodes of the cluster (instance store volumes) persists data only during the life of its EC2 instance (temporary storage).
Deployment options
There are several deployment options available for Amazon EMR cluster resources in the Amazon Web Services:
- Amazon EMR on EC2
- Amazon EMR on EKS
- Amazon EMR on Outpost
Depending on the usage, each cluster run on EC2, EKS, or Outpost can be long-running or transient (temporary).
Amazon EMR Serverless is a separate model that allows you to focus on the BigData processing applications and completely forget about EMR cluster management.
EMR Studio
Amazon EMR has an EMR Studio, an integrated development environment (IDE) that makes it easy for data scientists and engineers to develop, visualize, and debug data science and data engineering applications written in R, Python, Scala, and PySpark.
EMR Studio provides fully managed Jupyter Notebooks and the required tools to simplify interactive analytics tasks, application debugging, custom kernels and libraries management, and the organization of a collaborative development process.

Free hands-on AWS workshops
For gaining hands-on experience with AWS EMR, we strongly suggest you check out EMR AWS workshops:
