AWS outage – Simple way to protect yourself
Any company that uses Amazon Web Services (AWS) knows that outages can happen. So what can you do to protect yourself from AWS outages? The first step is to understand the principles of the reliability engineering platform for the AWS platform. These principles are designed to help reduce the impact of outages by identifying and addressing potential problems before they cause disruptions.
The second step is to plan how to respond to an AWS outage ahead of the disaster. This plan should include steps for how you will communicate with your customers and employees, how you will continue to provide essential services, and how you will minimize the impact of the outage on your business. The third step includes automated resiliency testing for your application and cloud infrastructure and continuously improving them to reduce disaster risks. These steps can help ensure that you are prepared for an AWS outage.
Table of contents
What is the AWS outage?
The AWS outage (or AWS cloud platform outage) is a term used to describe a situation in which one or many cloud computing services are unavailable. This can happen for various reasons, including hardware failures, software bugs, or network device problems. Outages can significantly impact businesses that rely on cloud services, as they can lose access to critical data and applications. In some cases, outages can even cause data loss. As such, businesses need contingency plans in case of a cloud platform outage.
Can AWS services go down?
Any of the AWS services may go down at any time without notice. This is because AWS is a cloud computing platform and, as such, is subject to the laws of physics. In particular, the heat from the sun can cause data centers to overheat, leading to service outages. Additionally, severe weather conditions can also lead to service disruptions. For example, hurricanes can knock out power lines, and flooding can damage equipment. Finally, earthquakes can also disrupt service by causing physical damage to infrastructure. Therefore, it is important to know that any AWS services may go down at any time and plan accordingly.
Everything fails, all the time.
Werner Vogels (CTO, Amazon.com)
Where to get the AWS status information?
The best place to get AWS cloud platform status information is the AWS Health Dashboard (AWS Status Page). This page provides real-time information on the health and performance of the AWS platform and its various services. The page displays each service’s “Operational” or “Degraded” status and a list of any current incidents. The page is updated in real-time, so it is always up-to-date. If you have any questions about the status of a particular service, you can contact AWS support through the page.
AWS Health Dashboard / AWS Status Dashboard
AWS Health Dashboard is the central place to get the most accurate and updated status information about the AWS cloud platform status. It includes information on outages, performance degradation, and other health events. The dashboard is updated in real-time, so you can always see the latest service availability and performance information. You can use the dashboard to stay informed about your AWS services’ health and troubleshoot issues by receiving events from Eventbridge. AWS Health Dashboard allows unauthenticated users to get general information about AWS service status updates across all AWS Regions and services.
The historical status of all AWS services
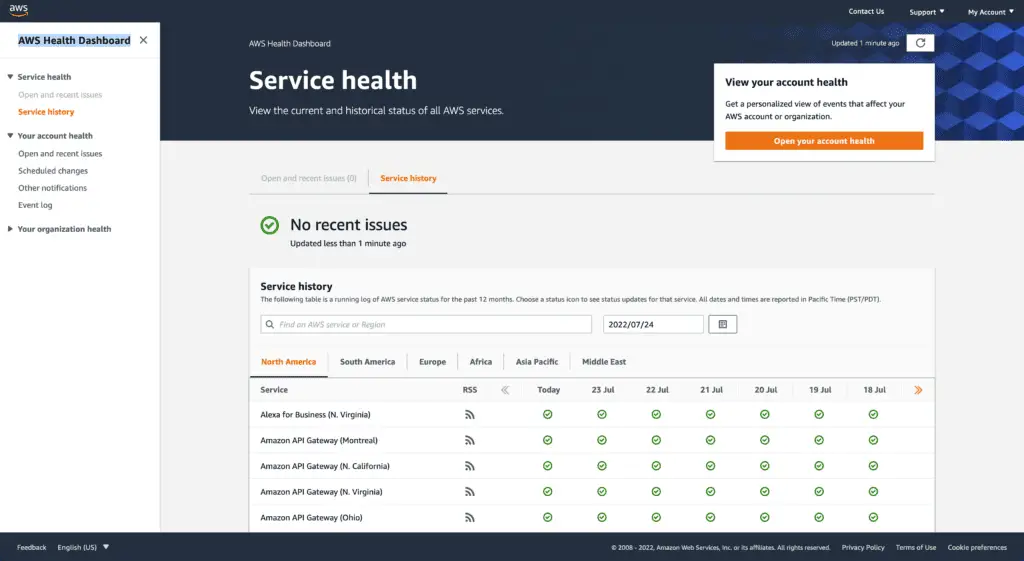
AWS Account Health status
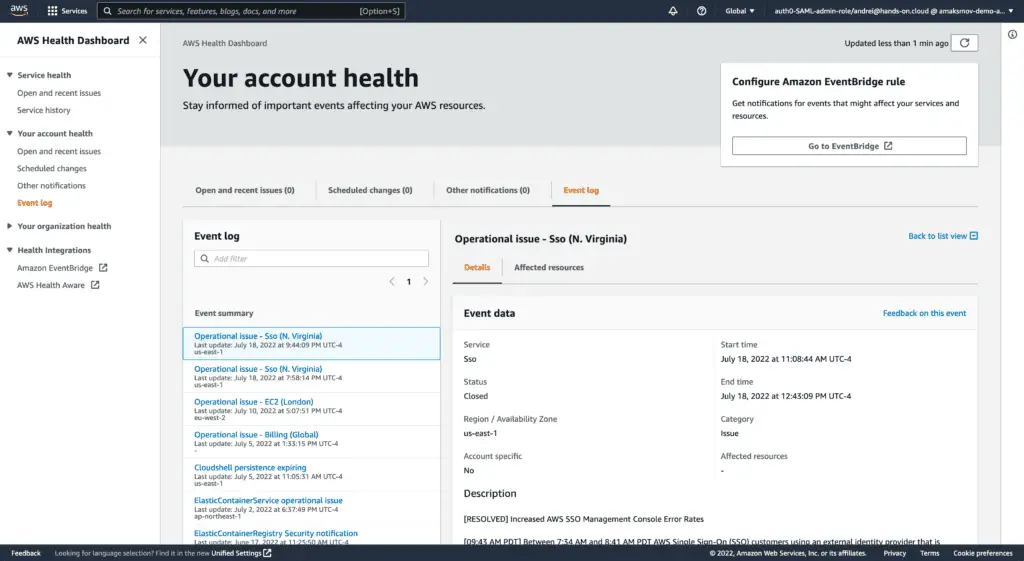
How must AWS engineers prepare for a disaster?
Shared Responsibility Model
Resiliency is a shared responsibility between AWS and its customers. It would be best to grasp how disaster recovery and availability function under this collaborative model.
AWS responsibility
AWS maintains the AWS Cloud infrastructure. The hardware, software, networking, and facilities that run AWS Cloud services are referred to as the cloud infrastructure. To ensure service availability meets or exceeds AWS Service Level Agreements (SLAs), AWS employs reasonable commercial efforts to keep these AWS Cloud services available.
The AWS Global Cloud Infrastructure enables customers to create highly resilient workload architectures. Each AWS Region is completely isolated, with distinct Availability Zones and infrastructure physically separated into numerous zones. Fault isolation protects resilience by preventing faults in one zone from affecting other zones in the Region. Over a fully redundant, dedicated metro fiber, which serves as the primary transport for inter-zone communications, AWS Zones are linked with high-bandwidth, low-latency networking (AWS backbone network). All traffic between zones is secured using encryption. Synchronous replication between zones is possible due to the network’s adequate performance. Companies are more isolated and protected from problems like outages, lightning strikes, tornadoes, hurricanes, and other disasters when their applications are split across AZs.
Customer responsibility
The services you select will determine your responsibility. This determines the amount of configuration work you must complete as part of your resiliency obligations. For example, a service such as Amazon Elastic Compute Cloud (Amazon EC2) necessitates that customers complete all necessary resiliency configuration and management activities. Customers who use Amazon EC2 instances must maintain control over multiple regions (such as AWS Availability Zones), implement self-healing using services like AWS Auto Scaling, and employ resilient workload architecture best practices for applications installed on the instances.
For managed services, such as Amazon S3 and Amazon DynamoDB, AWS operates the infrastructure layer, the operating system, and platforms, and customers access the endpoints to store and retrieve data. You are responsible for managing the resiliency of your data, including backup, versioning, and replication strategies.
To protect your applications from downtime, you should deploy them across multiple Availability Zones in an AWS Region. High-availability solutions isolate faults to one Availability Zone while maintaining service by leveraging the redundancy of the other zones. A Multi-AZ architecture is also part of a Disaster Recovery plan intended to increase the resiliency and security of your workloads. You can utilize multiple AWS Regions in disaster recovery plans. If the active Region cannot service requests, the workload service will fail from its active Region to its DR region in an active/passive configuration.
Well-Architected Framework
AWS engineers must be prepared for any disaster that might occur. AWS provides a Well-Architected Framework to help guide engineers in making their AWS architecture more reliable. The AWS Well-Architected Framework is a set of best practices for designing and building AWS applications. The framework is made up of six pillars:
- Operational Excellence
- Security
- Reliability
- Performance Efficiency
- Cost Optimization
- Sustainability Pillar
The Reliability Pillar includes strategies for building reliable systems on AWS Global Infrastructure. AWS Global Infrastructure is formed by AWS services designed to be highly available, scalable, and durable in case of Availability Zone or Regional failure.
To prepare for a disaster, AWS engineers should review the AWS Reliability Pillar for their applications and infrastructure and follow its guidance. They should also familiarize themselves with AWS Global Infrastructure and understand how to use it to build reliable systems. By following these guidelines, AWS engineers can ensure that their systems are prepared for disaster.
To simplify this process, AWS released a Well-Architected Framework Tool that allows you to assess your infrastructure and get recommendations based on AWS best practices.
Automated resilience testing
In today’s fast-paced world, organizations must be able to adapt to changes to compete rapidly. This means that their systems and applications must withstand unexpected failures without interruption. Automated resilience testing is a critical process within the organization to ensure that systems can meet this challenge. Organizations can automatically test for various failure scenarios to identify weaknesses before they cause an outage. Automated testing can help quickly identify and fix issues after a failure. As a result, automated resilience testing allows organizations to avoid downtime, reduce costs, and maintain a competitive edge.
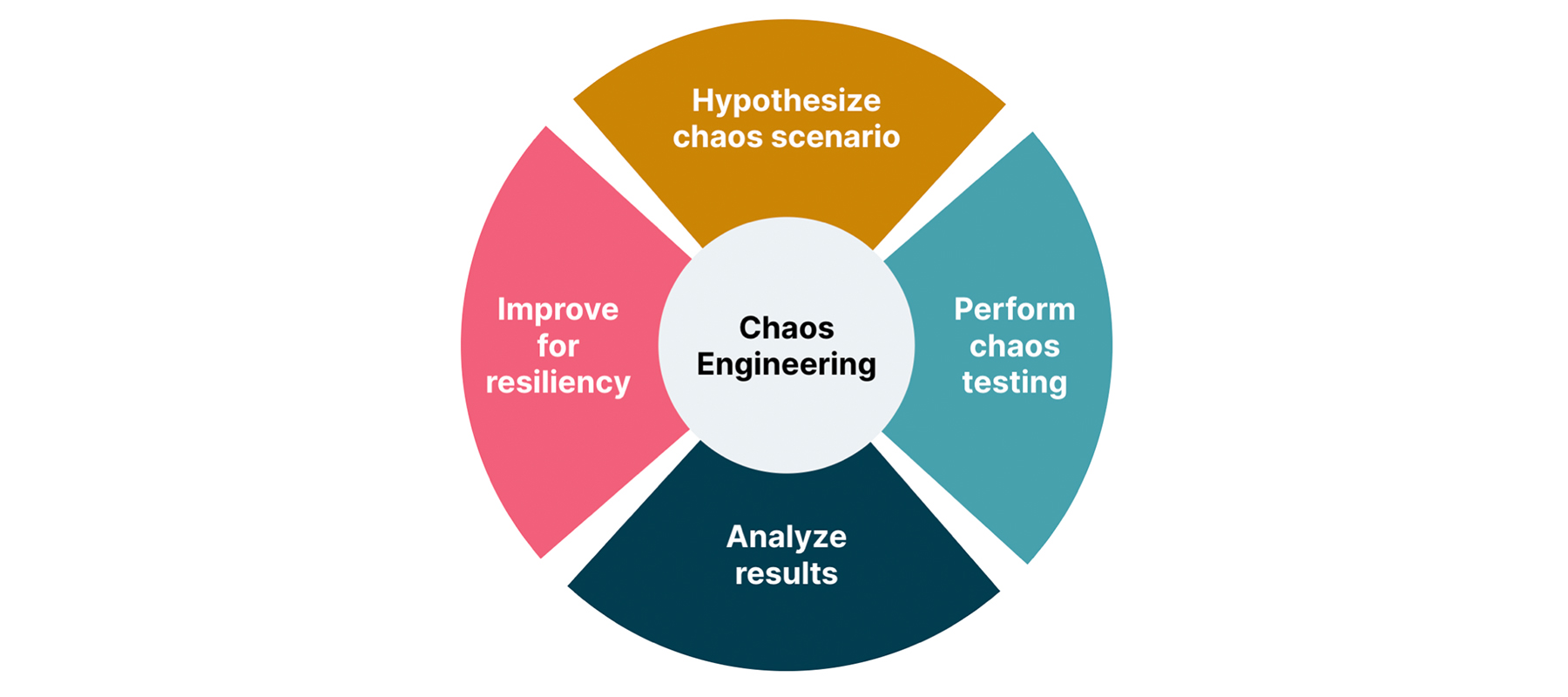
Automated resilience testing consists of several steps:
- Hypothesize chaos scenario – define a situation that might happen
- Perform chaos testing – automate and run test cases emulating such a scenario
- Analyze results – extract required metrics and analyze testing outcomes
- Improve for resiliency – make required changes in your application or infrastructure to mitigate the chaos scenario
Many open-source and paid tools are available on the market that can help you automate resiliency testing: Chaos Engineering tools comparison. Here are some well-known examples of these tools.
Chaos Monkey

Chaos Monkey is a software tool that helps to find potential weaknesses in system architectures by randomly shutting down servers and services (randomly terminates virtual machine instances and containers), and emulating cloud service interruption. By simulating failures, Chaos Monkey can help developers understand how their systems would react during an outage. In addition, Chaos Monkey can help to identify points of failure and bottlenecks in the system. By running regular tests with Chaos Monkey, developers can be confident that their systems are resilient and able to withstand unexpected failures.
You can find lots of useful information covering Chaos Monkey setup, configuration, and usage at Gremlin’s Chaos Monkey Guide for Engineers.
The tool supports Amazon Web Services, Google Compute Engine (Google Cloud), Azure (Microsoft Cloud), Kubernetes, and Cloud Foundry. It has been tested with AWS, GCE, and Kubernetes
ChaosBlade

ChaosBlade is an open-source toolkit designed to help developers test the resilience of their applications. It injects faults into the system, such as network delays, transient process failures, and application crashes. By simulating these conditions, ChaosBlade can help developers identify potential weaknesses in their code and prepare for them before they cause problems in production. In addition, ChaosBlade can also be used to test the performance of distributed systems under duress. By applying load to the system and injecting faults, it’s possible to see how well the system responds and identify any bottlenecks. ChaosBlade is a valuable tool for any developer working on distributed systems.
ChaosBlade works with containers, Kubernetes, bare metal, and cloud infrastructure.
Litmus
Litmus is open source Chaos Engineering platform that helps developers verify the resilience of Kubernetes applications in production. Litmus can identify weaknesses and vulnerabilities in application workflows by creating controlled failure scenarios. This enables developers to fix potential issues before they cause unplanned outages or impact customer experience. In addition, Litmus provides valuable insights into how an application behaves under duress, helping to improve its overall resilience. As a result, Litmus is essential for any team looking to improve their Kubernetes applications’ stability.
Litmus has amazing documentation, and step-by-step tutorials help to simplify learning the technology in hours.
Gremlin
Gremlin is a reliability engineering platform that enables developers to test the resilience of their systems in production by executing tests emulating unexpected behavior. Gremlin helps developers identify and fix potential issues by simulating real-world conditions before they cause user problems. Ultimately, this results in more reliable and user-friendly systems. Gremlin is easy to use and integrates with popular monitoring tools like New Relic and DataDog. Gremlin offers many features, including support for multiple programming languages, flexible scheduling, and customizable reporting. Whether new to reliability engineering or an experienced practitioner, Gremlin can help you build more resilient systems.
From my point of view, Gremlin is the most feature-reach reliability engineering and resiliency testing platform nowadays.
Summary
This article describes potential reasons for AWS outage, AWS and its customers’ responsibility model in case of disaster, the resiliency pillar of the Well-Architected framework, and software tools for automated resilience testing.
