You’ve probably heard of Amazon Athena if you’re a Big Data or Cloud Engineer. But what is it, and how can you get started with it?
AWS Athena is a Serverless query service that makes it easy to analyze data stored in Amazon S3 using standard SQL. It is a distributed SQL query engine designed to make working with large data sets fast, efficient and cost-effective. In combination with other AWS services, AWS Athena offers lots of value for anyone who needs to analyze lots of data quickly and accurately.
In this quick getting started guide, we’ll show you how to start with Athena so that you can start analyzing your data immediately. So let’s dive in!
Table of contents
What is Amazon Athena?
AWS Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Behind the scenes, Athena is built on top of the Presto engine and uses Amazon S3 as an underlying data store. With Athena, you can run interactive queries using SQL statements on multiple types of data stored on S3 – without being constrained by schema or having to load your data first. As such, AWS Athena offers tremendous value for businesses of all sizes that need to quickly and accurately analyze vast amounts of data with simple yet powerful SQL queries.

Athena use cases
- Query AWS services logs (ALB, VPC, CloudTrail, etc.)
- Business Intelligence (BI)
- Data Analytics
- Reporting
Athena supports standard data formats
- CSV
- JSON
- ORC
- Avro
- Parquet
Athena is a regional AWS service (AWS Global Infrastructure: Regions and Availability Zones).
Athena pricing
Athena pricing is very simple – you’re paying only for the fixed amount per TB of data scanned. For example, the current cost is $5/TB of data scanned in the US East (Ohio) region.
You only pay for the queries you run and don’t need any additional compute or storage resources to leverage its powerful features.
Note: AWS does not charge you for failed Athena queries, managing partitions’ queries or Data Definition Language (DDL) queries (CREATE TABLE, for example).
AWS services integrated with Athena
- AWS CloudFormation – You can use CloudFormation to configure Data Catalog, Named Queries (predefined SQL queries), and Workgroups (groups queries from other queries in the same account).
- Amazon CloudFront – You can use Athena to query CloudFront logs.
- AWS CloudTrail – Athena can query CloudTrail logs to enhance your analysis of AWS services activities in your AWS account or Organization.
- Elastic Load Balancing – you can track the source of traffic, latency, and bytes transferred to and from Elastic Load Balancing instances and backend applications by analyzing ALB logs.
- AWS Glue Data Catalog – create tables and query data in Athena based on a central unified metadata repository available throughout your Amazon Web Services account and integrated with the ETL and data discovery features of AWS Glue.
- AWS Identity and Access Management (IAM) – all Athena API actions are controlled by AWS IAM.
- Amazon QuickSight – Athena is commonly used with Amazon Quicksight (BI service) to create visual reports and dashboards and help you solve data analysis problems.
- Amazon S3 Inventory – you can use Athena to access Amazon S3 inventory to audit and report on the replication and encryption status of your objects for business, compliance, and regulatory needs
- AWS Step Functions – you can build fully-automated workflows, which may start and stop query execution, get query results, run ad-hoc or scheduled data queries, retrieve results from data lakes in Amazon S3, and send them to other AWS services.
- AWS Systems Manager Inventory – this integration allows you to query inventory data from multiple AWS Regions and accounts using Athena
- Amazon Virtual Private Cloud – you can inspect VPC, subnet, and EC2 instance traffic in AWS to investigate network traffic patterns and identify threats and risks across your Amazon VPC networks.
Setting up your environment for using AWS Athena
Before running your queries in Amazon Athena, you must set up a query result location in Amazon S3.
Open the Athena service in the AWS web management console and click the “Launch query editor” button:
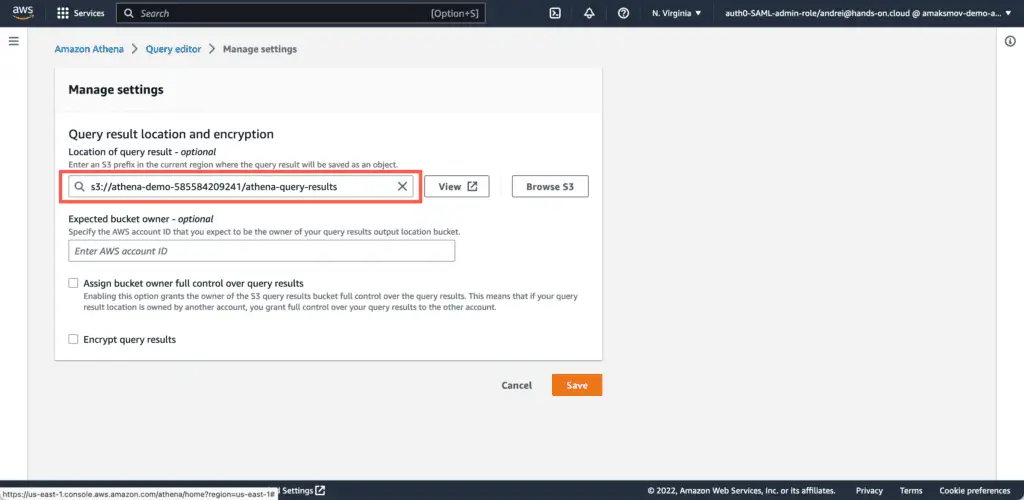
Click the “Edit settings” button in Athena Query Editor:

Specify an S3 bucket and S3 bucket path where you will store Athena query results. Optionally, enable encryption to force Athena to store query results in the encrypted data format or change S3 objects’ access control settings. Finally, click the “Save” button.
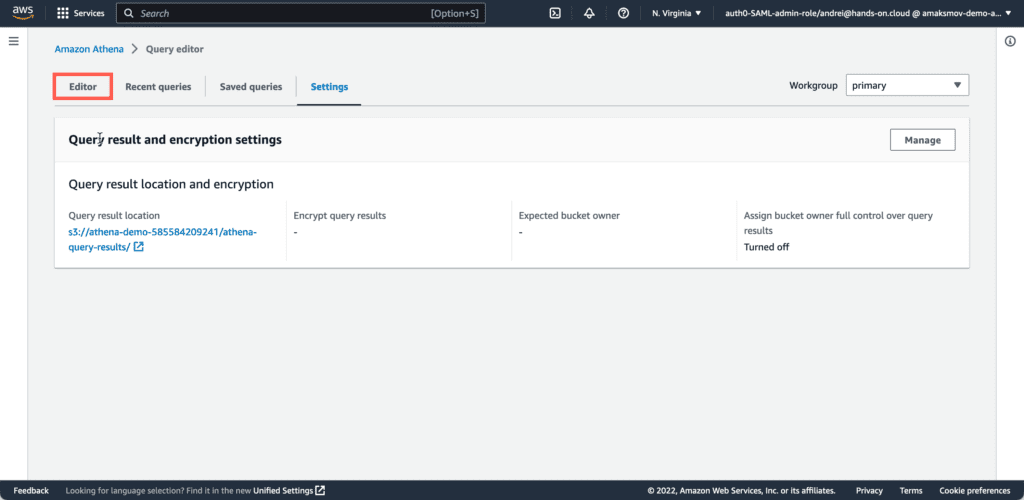
Now, you can come back to Athena Editor:
And start creating Athena databases and executing queries:

Your first query in AWS Athena
Querying data stored in AWS S3 with Amazon Athena can be a highly efficient way of extracting and analyzing data. With the Presto SQL query engine and access to all your data sources within AWS, Athena can run simple SQL queries or complex queries involving multiple joins, subqueries, and transformations.
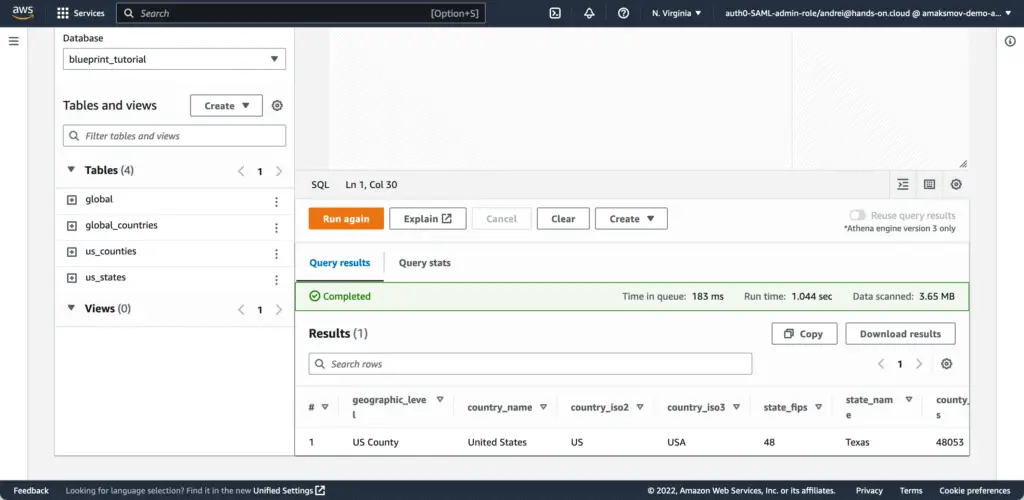
Let’s do a quick data analysis of one of the already existing demo tables in Athena.
In AWS Athena Query Editor, select:
- Data source:
AWSDataCatalog - Database:
blueprint_tutorial
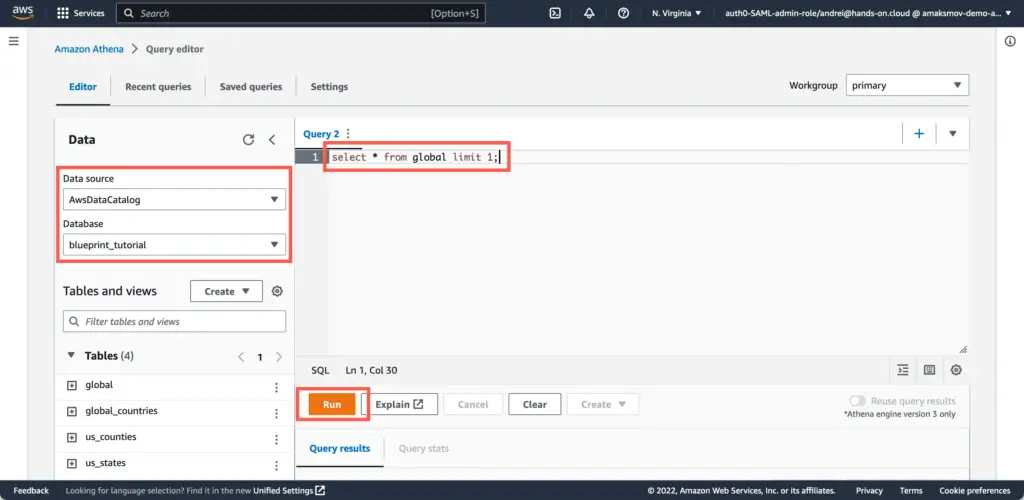
In the Query editor, type a simple query and execute it by pressing the “Run” button:
select * from global limit 1;As a result of query execution, you should get a dataset consisting of one row:
For a more complex example of configuring AWS Athena and QuickSight for analyzing VPC flow logs, check the “VPC Flow Logs – Complete Terraform solution” article. In this article, we’re building a complete infrastructure setup and automating everything using Terraform.
Of course, our example is very simple, but remember that Athena can handle the complex analysis of your data by executing large joins, window functions, and many more.
Federated queries
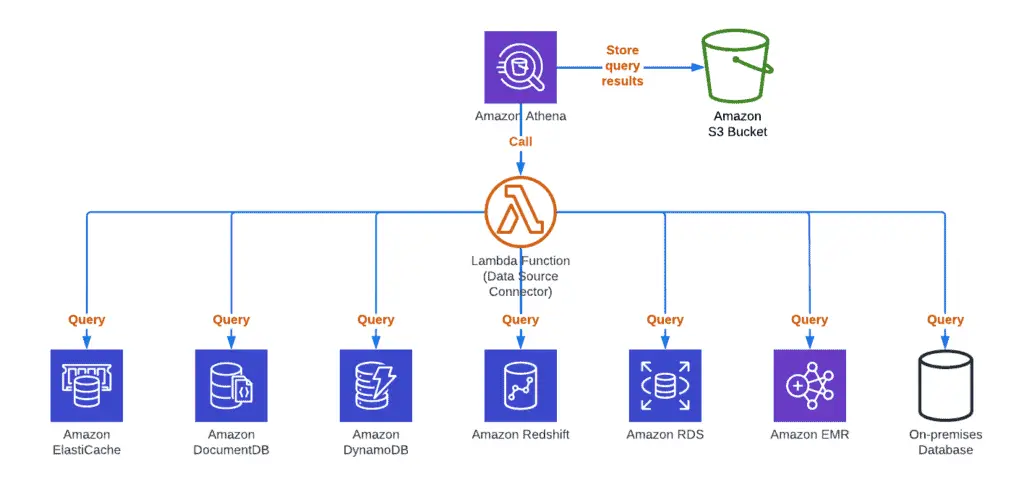
As an interactive query service, AWS Athena allows you to query your data not only in S3 buckets but also across any data stores in AWS and on-premises, for example:
- Relational DBs
- Non-relational DBs
- Object DBs
- Custom data sources using Athena Query Federation SDK (Java) or Unofficial Athena Query Federation SDK (Python).
To query these data stores, AWS Athena uses Data Source Connectors that run on AWS Lambda to query DynamoDB, RDS, CloudWatch Logs, or even 3rd-party APIs:
Tips and tricks for using AWS Athena
Utilizing AWS Athena is an excellent way to process and analyze large amounts of data quickly. Knowing certain tips and tricks when using this reliable service can help further increase its successful application.
Limiting queries during dev cycles
One key trick is limiting the number of records returned by queries from large datasets; these will help to save some money during dev cycles.
Use columnar data
Considering the AWS Athena pricing model, you can use columnar data in Apache Parquet or ORC formats. This will save some costs because you’ll be scanning fewer data. Using Apache Parquet or ORC formats will also give you a huge query performance improvement.
Note: if your data is in CSV or JSON formats, you can use the AWS Glue ETL job to convert it to Parquet or ORC.
Data compression
You are also interested in compressing your data to scan a smaller amount. You can use various compression algorithms, e.g., bzip2, gzip, lz4, zstd, snappy, and others.
Partition your data
When you know that you’re going to scan your data on the same columns continuously, you can organize (or partition) data in an S3 bucket using Apache Hive-style partitions, for example:
s3://your-s3-bucket/web-server-logs/year=2022/month=1/day=1/
s3://your-s3-bucket/web-server-logs/year=2022/month=1/day=2/
s3://your-s3-bucket/web-server-logs/year=2022/month=2/day=10/Alternatively, AWS Athena understands non-Hive style partitioning schemes. For example, CloudTrail logs and Kinesis Data Firehose delivery streams use separate path components for date parts:
s3://your-s3-bucket/web-server-logs/2022/01/01/
s3://your-s3-bucket/web-server-logs/2022/01/02/
s3://your-s3-bucket/web-server-logs/2022/02/10/Use large files
Accessing many small files causes lots of unneeded I/O overhead, which affects AWS Athena’s performance. Use files larger than 128 MB to minimize overhead and improve AWS Athena’s performance.
Additional tips
For more in-depth information on optimizing Athena queries, check the “Running SQL queries using Amazon Athena” part of the official AWS documentation.
Free hands-on AWS workshops
For gaining hands-on experience with Amazon Athena, we strongly suggest you check out Athena AWS workshops:
Summary
Amazon Athena is a fast, serverless query service that makes it easy to analyze data stored in Amazon S3 using standard SQL. This guide showed you how to set up your environment for using AWS Athena, write your first query, and some tips and tricks for using AWS Athena effectively. If you have any questions about using AWS Athena, be sure to check out our FAQ section. Was this guide helpful? Let us know what you think in the comments section below.
