An easy introduction to Artificial Neural Networks
Artificial Neural Networks (ANN) are a type of Artificial Intelligence (AI) designed to mimic how the human brain processes information. ANN consists of interconnected nodes, or neurons, that process information similarly to the human brain. You can use neural networks for various tasks, including pattern recognition and predictions. They are often used in areas where traditional methods of artificial intelligence struggle, such as image recognition and natural language processing. This article will cover the basics of Artificial Neural Networks (ANNs) and discuss how an Artificial Neural Network works.
Table of contents
As an Artificial Neural Network is the subset of Machine Learning, before starting with this article, ensure you have a solid knowledge of Machine Learning and its different types. Also, ensure you know about Supervised Machine Learning and Unsupervised Machine Learning.
What is Deep Learning?
Deep learning is a subset of Machine Learning concerned with learning data representations. Deep learning algorithms learn features or representations of data by progressively building layers of increasingly complex information. The aim is to eventually discover a rich representation to allow the algorithm to make accurate predictions about new data.
Deep learning is particularly effective for image recognition and natural language processing tasks. However, it is also computationally intensive and requires powerful hardware and sophisticated software.
A neural network with multiple hidden layers and multiple nodes in each hidden layer is known as deep learning. The word “deep” in Deep Learning refers to the number of hidden layers, i.e., the depth of the Neural network. Essentially, every neural network with more than three layers, including the Input Layer and Output Layer, can be considered a Deep Learning Model. Let us now understand the structure and terms associated with Neural networks.
Overview of Artificial Neural networks
As we discussed, Artificial Neural networks are composed of interconnected neurons that can transmit information to each other. Neural networks are similar to the brain because they are composed of interconnected processing elements or neurons that can learn to recognize input patterns.
Neural networks are composed of many interconnected processing elements or neurons that can learn to recognize input patterns. Neural networks are used for various tasks, including pattern recognition, classification, and prediction. Artificial neural networks are modeled after the biological neural networks that compose the brain.
Now let us understand some basic terms related to Artificial neural networks.
What is an Artificial neuron?
An artificial neuron is a mathematical function based on a model of biological neurons, where each neuron takes inputs, weighs them separately, sums them up, and passes this sum through a nonlinear function to produce output.
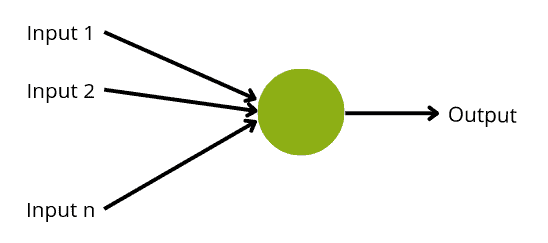
When neurons process the input in both artificial and biological networks, they decide whether the output should be passed on to the next layer as input. Whether or not to send information is called bias and is determined by an activation function built into the system. For example, an artificial neuron may only pass an output signal to the next layer if its inputs sum to a value above some particular threshold value.
The artificial neuron has the following characteristics;
- A neuron is a mathematical function modeled on the working of biological neurons.
- It is an elementary unit in an artificial neural network.
- One or more inputs are separately weighted.
- Inputs are summed and passed through a nonlinear function to produce output.
- Every neuron holds an internal state called an activation signal.
- Each connection link carries information about the input signal.
- Every neuron is connected to another neuron via a connection link.
What is perceptron?
The perceptron is a neural network unit that performs specific calculations to detect input data capabilities. In other words, a perceptron is a supervised binary classification learning algorithm that allows neurons to learn elements and process them one by one during preparation. The perceptron model is also treated as one of the best and most straightforward types of Artificial Neural networks. It consists of four main parameters:
- Input values
- weight and bias
- Net Sum
- Activation function
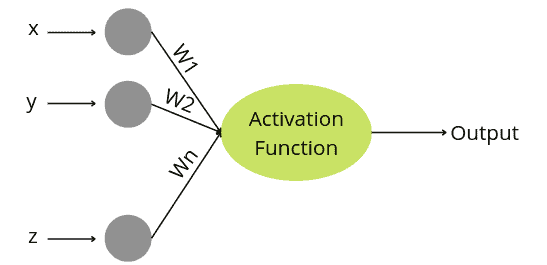
A perceptron has the following characteristics:
- Perceptron is an algorithm for Supervised Learning of single-layer binary linear classifiers.
- Optimal weight coefficients are automatically learned.
- Weights are multiplied with the input features, and a decision is made on whether the neuron is fired.
- The activation function applies a step rule to check if the output of the weighting function is greater than zero.
- If the sum of the input signals exceeds a certain threshold, it outputs a signal; otherwise, there is no output.
The internal structure of Neural networks
The Neural Network architecture is made of individual units of Neurons. When multiple neurons are stacked together in a row, they constitute a layer. Neural networks consist of layers of Neurons. The three main layers of neurons in Neural networks are:
- Input Layer
- Hidden Layer
- Output Layer
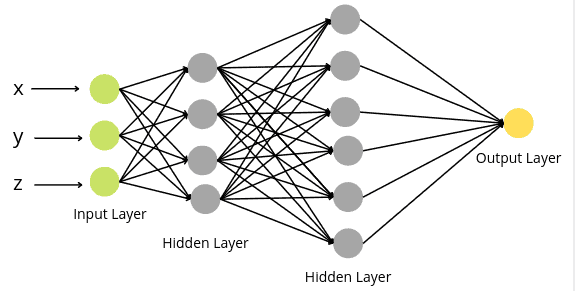
The input layer is the very beginning of the workflow for the artificial neural network. The input layer of a neural network is composed of artificial input neurons and brings the initial data into the system for further processing by subsequent layers of artificial neurons. One of the distinct characteristics of the input layer is that artificial neurons in the input layer have a different role to play because this layer does not take in information from previous layers because they are the very first layer of the network. In general, artificial neurons are likely to have a set of weighted inputs and functions based on those weighted inputs – however, in theory, an input layer can be composed of artificial neurons that do not have weighted inputs.
A hidden layer is a layer between input and output layers, where artificial neurons take in a set of weighted inputs and produce an output through an activation function. Hidden neural network layers are set up in many different ways. In some cases, weighted inputs are randomly assigned. In other cases, they are fine-tuned and calibrated through backpropagation. Either way, the artificial neuron in the hidden layer works as a biological neuron in the brain – it takes in its probabilistic input signals, works on them, and converts them into an output corresponding to the biological neuron’s axon.
The output layer in an artificial neural network is the last layer of neurons that produces given outputs for the program. There is only one node in the output layer if the neural network is for the prediction of binary classification or a regression problem. While for multi-class classification, there can be multiple Nodes in the output layer depending on the number of output classes in the dataset.
Different activation functions
An activation function defines how the weighted sum of the input is transformed into an output from a node or nodes in a network layer. The choice of activation function significantly impacts the capability and performance of the neural network, and you may use different activation functions in different parts of the model.
Except for the input layer, all other layers have activation functions. Usually, all hidden layers typically use the same activation function. The output layer typically uses a different activation function from the hidden layers, which depends on the model’s type of prediction.
Activation functions for Hidden layers
A hidden layer in a neural network is a layer that receives input from another layer and provides output to another layer. The three most commonly used activation functions in Hidden layers are:
- Rectified Linear activation (ReLu)
- Logistic activation function (sigmoid)
- Hyperbolic Tangent (Tanh)
Let us understand each function and plot them on a graph using Python.
Rectified Linear activation function
The rectified linear activation function, or ReLU for short, is a piecewise linear function that will output the input directly if it is positive. Otherwise, it will output zero. It has become the default activation function for many neural networks because a model that uses it is easier to train and often performs better.
The ReLU function is calculated using the following formula:
max(0, x)
If the input value (x) is negative, the output will be 0. Otherwise, the value (x) is returned.
Let’s now plot the ReLU using the Python programming language.
# importing the module
import matplotlib.pyplot as plt
# rectified linear function
def rectified(x):
return max(0.0, x)
# define input data in range of -5 to 5
inputs = [x for x in range(-5, 5)]
# calculate outputs
outputs = [rectified(x) for x in inputs]
# ploting ReLU function
plt.plot(inputs, outputs)
plt.show()Output:
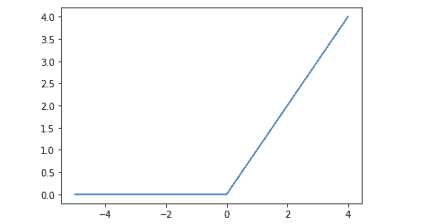
Notice that for negative values, the output is zero.
Sigmoid activation function
The sigmoid activation function, also called the logistic function, is traditionally a popular activation function for neural networks. The input to the function is transformed into a value between 0.0 and 1.0. It is commonly used for models where we have to predict the probability as an output. Since the probability of anything exists only between 0 and 1, sigmoid is the right choice because of its range.
The sigmoid activation function uses the following equations:
1/(1 + e ^ -x )
Let us now plot the sigmoid activation function.
# importing the module
from math import exp
# sigmoid activation function
def sigmoid(x):
return 1.0 / (1.0 + exp(-x))
# define input in range of -10 to 10
inputs = [x for x in range(-10, 10)]
# calculate outputs
outputs = [sigmoid(x) for x in inputs]
# ploting sigmoid function
plt.plot(inputs, outputs)
plt.show()Output:
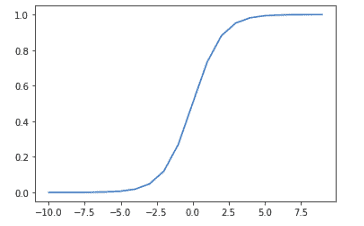
Notice that the output is between 0 and 1.
A hyperbolic tangent activation function
The hyperbolic tangent activation function is also referred to simply as the Tanh function. It is similar to the sigmoid activation function and has the same S-shape. But the Tanh function takes any real value as input and outputs values from -1 to 1.
The following is the mathematical equation for the hyperbolic tangent activation function.
(e ^x – e ^-x) / (e^x + e^-x)
Let us also plot the Tanh activation function.
# tanh activation function
def tanh(x):
return (exp(x) - exp(-x)) / (exp(x) + exp(-x))
# define input data in range -5 t0 5
inputs = [x for x in range(-5, 5)]
# calculate outputs
outputs = [tanh(x) for x in inputs]
# plot inputs vs outputs
plt.plot(inputs, outputs)
plt.show()Output:
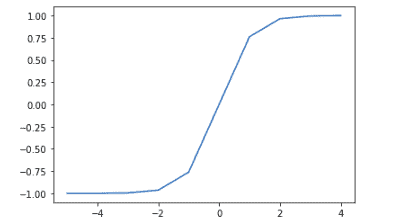
Notice that the Tanh activation function output is from -1 to 1.
Activation functions for the Output layer
The output layer directly outputs the predictions of the model. The activation function for the output layer mainly depends on the type of output classes. The most popular activation functions for the output layer are:
- Linear activation function
- Sigmoid activation function
- Softmax activation function
We had already discussed the sigmoid activation function. In this section, we will cover the other two functions.
Linear activation function
The linear activation function is called the identity function, which multiplies the input value by 1. In other words, the linear activation function does not change the weighted sum of the input in any way and returns the value directly.
Let us plot the linear activation function.
# linear activation function
def linear(x):
return x
# input data from -10 to 10
inputs = [x for x in range(-10, 10)]
# calculate outputs
outputs = [linear(x) for x in inputs]
# plot linear activation function
pyplot.plot(inputs, outputs)
pyplot.show()Output:
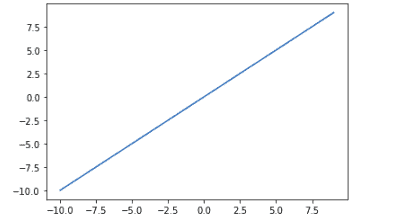
Notice the output of the function is the same as the input.
Softmax activation function
The softmax function is the activation function in the output layer of neural network models that predict a multinomial probability distribution. Softmax is used as the activation function for multi-class classification problems where class membership is required on more than two class labels.
It uses the following equation:
e^x / sum(e^x)
let us now use Python to find the probability for multi-class.
# importing module
from numpy import exp
# softmax activation function
def softmax(x):
return exp(x) / exp(x).sum()
# input data
inputs = [1.0, 3.0, 2.0]
# calculate outputs
outputs = softmax(inputs)
# probabilities
print(outputs)Output:
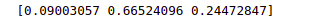
Notice that the softmax function returns the probability for each input class.
Different types of Neural network
Now, we are familiar with various types of activation functions used in Neural networks. This section will discuss the three most commonly used neural networks in deep learning. Let us also discuss the kind of Neural networks you can use for predictions.
Feedforward Neural Network
A feedforward neural network is an artificial neural network where connections between the units do not form a cycle. In this network, the information moves in only one direction(forward), from the input nodes, through the hidden nodes (if any), and to the output nodes. There are no cycles or loops in the network.
There are two basic types of feedforward neural networks.
- Single-layer perceptron
- Multi-layer perceptron
A Single-layer perceptron is the simplest Feedforward Neural Network and does not contain any hidden layer, which means it only consists of the input layer and layer output nodes.
A Multi-layer perceptron consists of multiple layers of computational units, usually interconnected in a feedforward way. It consists of the input layer, hidden layer (at least one), and output layer. Each neuron in one layer has directed connections to the neurons of the subsequent layer.
Convolutional neural network
A Convolutional Neural Network (CNN or ConvNet) is a network architecture for deep learning that learns directly from data, eliminating manual feature extraction. CNNs are particularly useful for finding patterns in images to recognize objects, faces, and scenes. They can also be quite effective for classifying non-image data such as audio, time series, and signal data.
A convolutional neural network consists of an input and an output layer and multiple hidden layers.
The hidden layers of a CNN typically consist of a series of convolutional layers that convolve with multiplication or other dot product. Usually, ReLU is used comely as an activation function.
Recurrent Neural Network
A recurrent neural network (RNN) is a special artificial neural network adapted to work for time series data or data involving sequences. RNNs have the concept of memory that helps them store the states or information of previous inputs to generate the next output of the sequence. Ordinary feedforward neural networks are only meant for data points independent of each other. However, suppose we have data in a sequence such that one data point depends upon the previous data point. In that case, we need to modify the neural network to incorporate the dependencies between these data points.
Constructing Neural Network
We can construct a neural network by following the steps below:
- Define the number of input layer nodes.
- Define the number of hidden layers nodes.
- Define the number of output layer node
- Apply activation functions on the hidden layers.
- Apply the activation function on the output layer.
Let us now construct a neural network for the following dataset.

As you can see, there are four different input variables. That means the number of nodes in the input layer will be four.
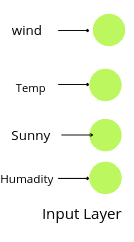
Notice that the input layer does not take any activation function as they take the data and transfer it to the next layer. The number of nodes in the input layer should equal the number of input variables.
The next step is to define the number of hidden layers and the number of nodes in each layer. There is no such process to find the optimum number of hidden layers or the number of nodes. It is a kind to try and error method. In this example, we will have two hidden layers.
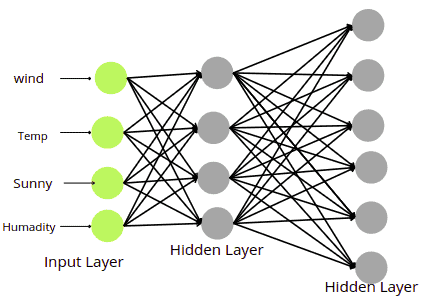
You can apply almost all activation functions in the hidden layer except softmax.
The output layer depends on the output class of the dataset. If the dataset is a binary classification or a regression dataset, then there will be only one node in the output layer, as shown below:
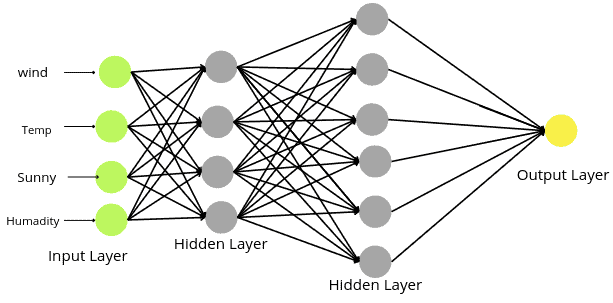
In the case of binary classification, the activation function in the output layer should be sigmoid or Tanh. And in the case of a regression problem, the activation function must be linear.
If the dataset has multiple output categories, let us say 3, then there will be three nodes in the output layer, each representing different outputs as shown below:
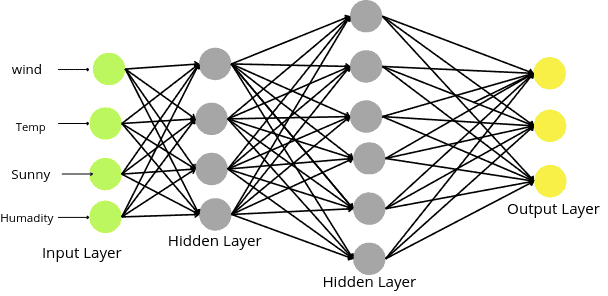
In the case of multi-class classification, the activation function on the output layer should be Softmax.
Summary
Neural Network is a series of algorithms that endeavors to recognize underlying relationships in a data set similar to how the human brain operates. It mainly consists of three layers: input, hidden, and output. This article covered Neural Network layers, activation functions, and how they form a Neural Network.
