Unsupervised Learning: Easy explanation of ML concepts
Unsupervised Machine Learning is a set of Machine Learning algorithms in which the model uncovers hidden patterns and insights from provided unlabeled datasets. This article covers Unsupervised Machine Learning basics, problems, algorithms, and example applications.
Table of contents
Unsupervised Machine Learning uses different algorithms to analyze and cluster unlabeled datasets. It allows to find similarities and differences in information and makes it ideal for exploratory data analysis, cross-selling strategies, customer segmentation, and image recognition.
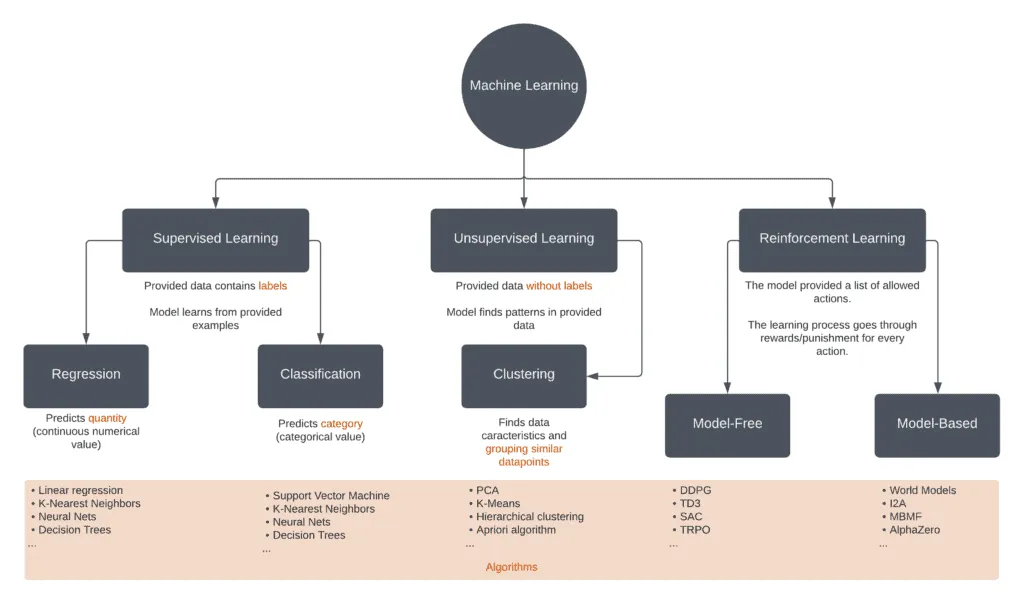
What is Unsupervised Machine Learning?
Unsupervised Machine Learning is a technique that teaches machines to use unlabeled or unclassified data. The idea is to expose computers to large volumes of varying data and allow them to learn from it to provide previously unknown insights and identify hidden patterns.
Unsupervised machine learning algorithms are used to learn from data that is not labeled or classified. Instead of being given explicit instructions, the algorithm must learn to recognize patterns independently. This can be done in several ways, but most algorithms use some form of training data. This data can be used to teach the algorithm about different features and how they are related. For example, if the training data includes images of cats and dogs, the algorithm will learn to identify features that are common to both cats and dogs.
Once the algorithm recognizes these features, it can be applied to new data sets to classify them. While unsupervised learning is more difficult than supervised learning, it can be more effective in certain situations. For example, if there is a lot of training data available, unsupervised learning can help to find hidden patterns that would be difficult for humans to find.
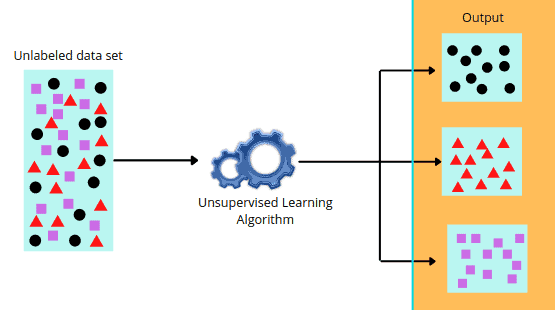
Unsupervised Machine Learning is very much similar to how a human learns. Assume you’ve never had ketchup or chili sauce before. You’ll be able to tell the difference between two unlabeled bottles of ketchup and chili sauce if you’re given two unlabeled bottles of each and asked to taste them. You’ll also be able to distinguish between the two sauces (sour and spicy) even if you don’t know their names.
Tasting each one a few more times will familiarize you with the flavor. Soon, you’ll be able to categorize dishes depending on the sauce they’ve been served simply by tasting them. The provided example is similar to how machines identify patterns and classify data points with the help of Unsupervised Learning.
Unsupervised vs. Supervised Machine Learning
Machine Learning can be broadly divided into unsupervised and supervised learning. Unsupervised learning is where the data is not labeled, and the algorithm must learn from it. Supervised learning is where the data is labeled, and the algorithm learns from the labels. Unsupervised learning is generally more difficult because the data is more unstructured.
However, it can be more powerful because it can learn from complex patterns that supervised learning might miss. For example, unsupervised learning can be used for anomaly detection, while supervised learning is typically used for classification tasks. There are many different types of unsupervised and supervised learning algorithms, so choosing the right one for a given task is an important area of research.
For more information about Supervised Learning, check out the Introduction to Supervised Machine Learning article.
Unsupervised machine learning algorithms are designed to work with unlabeled input data. These algorithms aim to find structure in the data and then to learn a model that can be used to generate output data. There are many different types of unsupervised machine learning algorithms, but they all share a common goal: to find structure in unlabeled data. To do this, unsupervised machine learning algorithms first need to identify patterns in the data.
Once these patterns have been identified, the algorithm can then learn a model that can be used to generate output data. The process of finding patterns in data and then learning a model is called cluster analysis. Unsupervised machine learning algorithms can find structure in data because they are not limited by the constraints of labeled data. This allows them to identify more complex patterns than supervised machine learning algorithms.
In addition, unsupervised machine learning algorithms are often more computationally efficient than supervised machine learning algorithms. This is because they do not need to track the labels of the input data. As a result, unsupervised machine learning algorithms can be used to find structures in large datasets that would be too computationally expensive for supervised machine learning algorithms.
Unsupervised Learning pros and cons
The most significant advantage of Unsupervised Learning is that the machine can analyze extensive datasets and find relationships within data that people can’t see. In addition to that, it might be helpful when we don’t know what information we are looking for.
The following are some common advantages that make Unsupervised Machine Learning very important:
- As Unsupervised Learning solves the problem of classifying data without prior labeling it
- Unsupervised learning allows for reducing computational requirements for Supervised Learning algorithms by detecting and removing less important features from the dataset (dimensionality reduction)
- The outcome of an Unsupervised Learning algorithm can yield entirely new business opportunities and revenue
- Unsupervised Learning can help to understand large amounts of raw data, making it an ideal tool for data scientists
While Unsupervised Learning has many benefits, some challenges can occur when it allows Machine Learning models to execute without human intervention. Some of these challenges can be:
- The implementation might be costly as algorithm results usually require human intervention to understand outcomes patterns and correlate them with the domain knowledge
- Continuous model feeding will live data may result in inaccurate and time-consuming results
- The complexity and computational requirements increase with the number of features to process
- It is not always clear that the obtained results will be useful (domain knowledge required for clarification)
Common algorithms
Unsupervised machine learning algorithms are used to find patterns in data. common unsupervised algorithms include cluster analysis, association rule learning, and dimensionality reduction. Cluster analysis is used to group data points based on similarity.
Association rule learning is used to find relationships between variables. Dimensionality reduction is used to reduce the number of variables in a dataset. These algorithms are often used together to find hidden patterns in data.
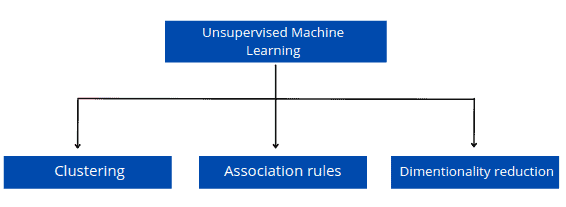
Machine learning is a rapidly growing field with many applications in business and science. As more data is collected, unsupervised algorithms will play an increasingly important role in finding hidden patterns and insights.
Cluster analysis
In unsupervised machine learning, cluster analysis groups unlabeled input data into meaningful output data. This output data can be used to understand the structure of the input data better or to make predictions about unlabeled data. There are many different ways to perform cluster analysis, but the most common method is to use a model that groups input data based on similarity.
This similarity can be based on features like location, race, or gender. Once the model has been created, it can group unlabeled input data into output clusters. Cluster analysis is a powerful tool for understanding complex datasets and can be used to make predictions about unlabeled data.
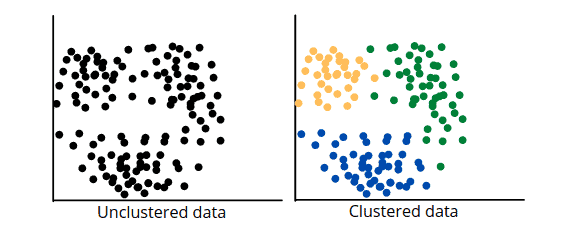
The most common clustering algorithms are:
- K-means clustering is a type of clustering in which data points are assigned into K groups, where K represents the number of clusters based on the mathematical distance of each data point from each group’s centroid.
- Hierarchical clustering or hierarchical clustering analysis is a technique that groups similar objects into groups called clusters. This technique allows you to build tree structures (clusters) from similar data to see how different sub-clusters relate to each other
- Probabilistic clustering allows for a group of data points based on the likelihood of their belonging to a particular distribution. The Gaussian Mixture Model (GMM) is one of the most commonly used probabilistic clustering methods.
Association rules
Association rules are an Unsupervised Machine Learning algorithm used to discover relationships between items in unlabeled input data. The algorithm’s output is a set of association rules that can be used to predict future items. Association rules are often used in market basket analysis, where the goal is to find relationships between purchased products.
For example, a retailer might use association rules to identify customers likely to purchase a particular product if they have purchased another one. Association rules can also be used for other applications, such as fraud detection and recommendation systems.
Association rule learning works on the If and Else Statement concept, such as if A then B.

Some of the association rule algorithms are:
- Apriori algorithm is an algorithm for frequent itemset mining and association rule learning over relational databases’ data (large datasets). The algorithm identifies the frequent individual items in the database and extends them to larger and larger item sets as long as those item sets appear sufficiently often in the database. For example, you can use this algorithm to upsell additional products to already selected ones by the customer.
- ECLAT algorithm is similar to the Apriori algorithm, but it is better suited to small and medium datasets.
- FP-growth Algorithm is the improved version of the Apriori Algorithm, it represents the database in the form of a tree structure to extract the most frequent patterns from the data.
Dimensionality reduction
In machine learning, dimensionality reduction reduces the number of features in a data set. This can be done for various reasons, such as increasing the speed of a learning algorithm, reducing the amount of data required to train a model, or improving the accuracy of predictions.
There are many different techniques for dimensionality reduction, but they all aim to simplify data while preserving as much information as possible. In unsupervised machine learning, dimensionality reduction is often used to reduce the data to a lower-dimensional space that is more easily interpretable by humans.
This can help visualize data sets with many features or find clusters of data points with similar characteristics. By reducing the dimensionality of input data, we can gain valuable insights into the structure of complex data sets.
Some of the standard dimensionality reduction techniques are:
- Principal component analysis (PCA) is a dimensionality reduction approach that uses feature extraction to reduce redundancies and compress datasets. The idea of PCA is simple — reduce the number of variables of a dataset while preserving as much information as possible.
- Singular value decomposition is a matrix decomposition method for reducing a matrix to its constituent parts in order to make subsequent matrix calculations simpler.
Applications examples
Unsupervised learning algorithms are used to find patterns in data objects without being given any labels. This can be useful for clustering, density estimation, and outlier detection tasks. Some common unsupervised learning algorithms include k-Means Clustering, Support Vector Machines, and Decision Trees. Application examples that use unsupervised machine learning include supply chain management, fraud detection, recommender systems, and image processing.
In supply chain management, unsupervised learning algorithms can be used to find patterns in data that can help improve the efficiency of the supply chain.
In fraud detection, unsupervised learning algorithms can find abnormal data patterns that may indicate fraud. In recommender systems, unsupervised learning algorithms can find patterns in data that can help recommend items to users.
In image processing, unsupervised learning algorithms can be used to find patterns in images that can help improve the quality of the images.
Typical real-life application examples of Unsupervised Machine Learning are:
- Document Clustering retrieves information from a text document, we can use the K-Means algorithm to organize documents, topic extraction, and filtering.
- Data Reduction can be applied during the stage of data preparation for Supervised Machine Learning to eliminate redundant and junk data, leaving only the most important features of the dataset.
- Anomaly Detection – Unsupervised learning helps detect fraud by reacting to nontypical data points in the dataset (CloudWatch anomaly detection)
- Social Media Platforms – Unsupervised Learning algorithms can help to extract relationships between different users to suggest posts or ads (Facebook feed)
- News Sections – Google News uses Unsupervised Learning to categorize articles from various news websites by categories on their website.
Summary
Unsupervised Machine Learning uses unlabeled and unclassified data to find datasets’ relations and hidden patterns. The most common algorithms of Unsupervised Learning are Clustering and Association rules. This article provides an overview of Unsupervised Learning and its algorithms.
