Machine Learning Introduction: Easy AI Journey
Machine learning (ML) enables computers to learn from past data using various algorithms to make predictions. Common applications include image analysis, speech recognition, recommendation systems, and chatbots. This article covers fundamental concepts, training models, and popular Python packages. Additionally, it includes an overview of machine learning services provided by AWS.
To train these models, training examples or training sets are used to teach the algorithm how to recognize patterns in the data. This article is a simple introduction to Machine Learning, which covers the basic concepts of Machine learning, including different types of learning, frameworks for building ML systems, and popular Python packages that you can use in the Machine Learning space. Finally, we’ll cover the broadest and deepest set of machine learning services the AWS cloud provides. These services put machine learning in the hands of every developer, data scientist, and expert practitioner.
What is Machine Learning
Machine Learning (ML) is a branch of computer science that evolved from pattern recognition and computational learning theory in Artificial Intelligence (AI). Data scientists now widely use ML to develop chatbots with natural language processing capabilities, which require large amounts of training data.
Machine Learning can be defined in different ways. One of the ways to define Machine Learning is as a subset of artificial intelligence that involves training data and examples to enable computers to learn and improve their performance on specific tasks, such as computer vision or chatbots.
Field of study that provides computers the ability to learn without being explicitly taught Arthur Samuel, an American pioneer in the fields of ML and AI
In other words, Machine Learning is a subfield of computer science that involves using statistical approaches to develop computer systems that automatically improve performance over time or spot patterns in large volumes of data that people would be unlikely to notice.
Learning algorithms work based on the theory that strategies, algorithms, and inferences that worked well in the past will likely continue working well. These algorithms build a model based on sample data, known as training data (the data known from the past), to make predictions or decisions without being explicitly programmed. The development of neural networks has greatly advanced research in learning algorithms, allowing more complex models to be created. Additionally, statistics play a crucial role in analyzing the performance of these algorithms and improving their accuracy.
A subset of Machine Learning relevant to data scientists is closely related to computational statistics, which focuses on making predictions using a mathematical model and training data. However, not all ML involves decision trees or statistical learning.
While handling the basics, we must cover several other terms related to Machine Learning, such as training data, data scientists, training set, and algorithm.
- Artificial intelligence is the broadest field of study, and its goal is to enable machines to behave like humans; by applying the idea of “rewarding” and “punishing” computers for correct or incorrect actions, people can teach machines to play computer games or drive cars, for example.
- Deep Learning is a subclass of Machine Learning algorithms that uses multiple layers to extract higher-level features from the raw data. Here, we’re speaking about neural networks or artificial neural networks (ANN) and trying to solve problems that are hard for humans to solve or develop algorithms for.
Here’s how Machine Learning, a subset of Artificial Intelligence, is related to Deep Learning, which uses neural networks as algorithms to learn from training data based on the artificial intelligence theory.
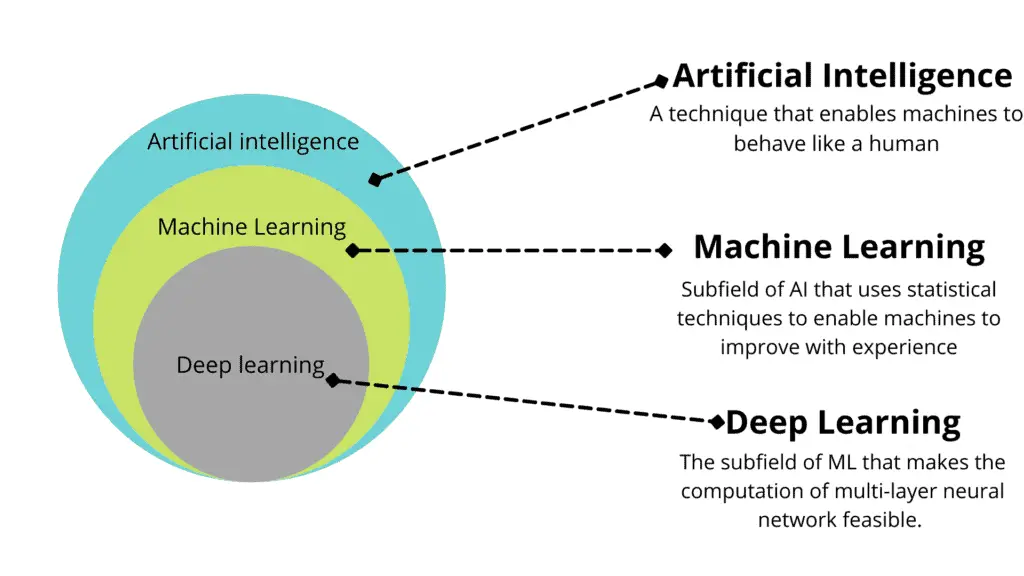
The mathematical part of Machine Learning deals with statistics, calculus, linear algebra, and probabilities.
When do we need to use Machine Learning?
Traditional programming involves defining and applying hand-coded rules to the data. However, this approach has two main issues when building intelligent systems: It is limited by the programmer’s ability to anticipate all possible scenarios and does not take advantage of machine learning approaches or methods. On the other hand, machine learning systems can learn from data and improve over time without being explicitly programmed with rules.
- Developers, computer scientists, or data engineers must devise rules to analyze the data manually, which might be extremely challenging, especially for large amounts of data. Many machine learning techniques, such as unsupervised and other algorithms, can automate this process.
- Developed rules might not apply to new unseen data, and a new rule set has to be generated. Machine Learning (ML) helps to generate such rules from past experiences automatically using algorithms and training systems, eliminating manual programming efforts (Arthur Samuel, 1959). This theory has been widely accepted in the field of ML.
So, Machine Learning is a theory of training machines to do tasks using methods that can learn from past experiences without relying on rule-based programming. In that case, all heavy lifting is shifted onto the machine, but we still have to provide a machine with some code and data to instruct it on how to learn/extract rules, which can be done through supervised learning methods.
As soon as machine learning rules are extracted, the trained machine learning model using various machine learning approaches can be further utilized to answer similar problems using unsupervised machine learning with new similar data through a machine learning program.
Why is Machine Learning so popular?
The ability of machine learning methods and systems to extract knowledge and insights from data with almost no programming effort, based on theory and training, faster and better than humans can do, makes machine learning so popular nowadays. At this moment in time, we have everything we need to utilize Machine Learning.
- Data: large amounts of data are easy to produce, collect and store
- Compute power supplies us with powerful processing CPUs/GPUs, hardware acceleration, and parallelization
- Algorithms are supported by a variety of ML frameworks and libraries improved for performance and use of the most efficient techniques
Terminology
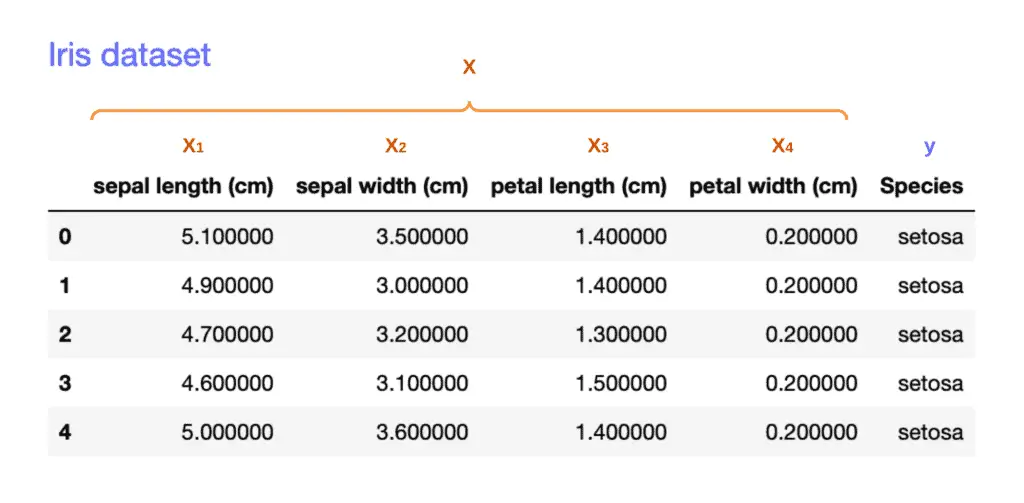
All data in the ML context is usually described as a set of features and labels.
A set of features (inputs) is usually denoted as X, and a single feature is usually denoted as x. Here are some features examples:
- Tabular data: string or numerical values organized in columns
- Images: numerical values of light intensities in pixels of images
- Language: strings of text snippets or words
- Multimodal: a combination of all the above
Labels in the dataset are outputs we try to predict. Labels can either be categorical or numerical values. They are usually denoted as y. Some datasets don’t have labels available (see Unsupervised learning). Here are some labels examples:
- Categories: book genre, text sentiment, flower type, etc.
- Numerical values: stock price, rating score, etc.
Here is an example of features and labels in the tabular dataset for supervised learning. The dataset is used to train deep learning models with various learning algorithms.
A Machine Learning algorithm is a set of instructions the computer can use to find the best rules out of the data. The simplest example of the algorithm is the linear regression algorithm, which creates continuous numerical values as the output. To produce such an output, the algorithm takes a weighted combination of input features:
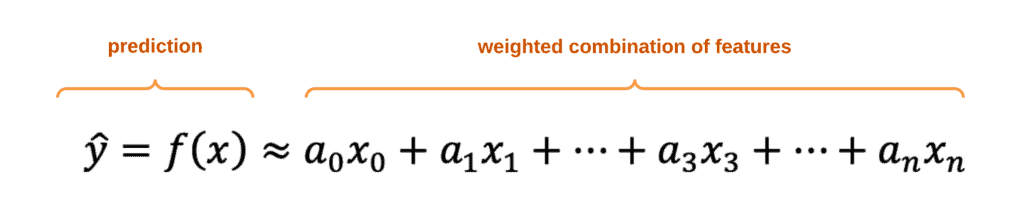
In mathematical notation, we denote the prediction as y hat or a function of x, where “x” features. Every feature x has a factor “a” in front of it. These factors are called weights or parameters, and they determine how much influence every feature has on the final output. Features might be positive or negative.
The algorithm aims to examine the provided data examples and find the best weights. The best values depend on the inputs. Every learning algorithm, including deep learning, has its way of training and finding weights. These artificial intelligence techniques are used to optimize the algorithm’s performance.
The calculated set of weights of mathematical equations of the specific ML algorithm is called the ML model, and the process of finding weights is called ML model training. The Machine Learning model lets machines quickly calculate the output (prediction) based on the inputs.
Types of Machine Learning Algorithms
A Machine Learning system learns from existing data through training, constructs prediction models, and predicts the result whenever fresh data is received. The more training data you use to educate the model, the more precise predictions you’ll get.
Machine Learning uses three classes of algorithms (three machine learning types):
- Supervised learning – these algorithms built a mathematical model from the historical data set containing inputs/features and desired outputs.
- Unsupervised learning – algorithms that focus on identifying patterns in data sets for data that is not classified or labeled.
- Reinforcement learning – focuses on algorithms that enable the machine to learn in an interactive environment by trial and error using feedback from their actions.
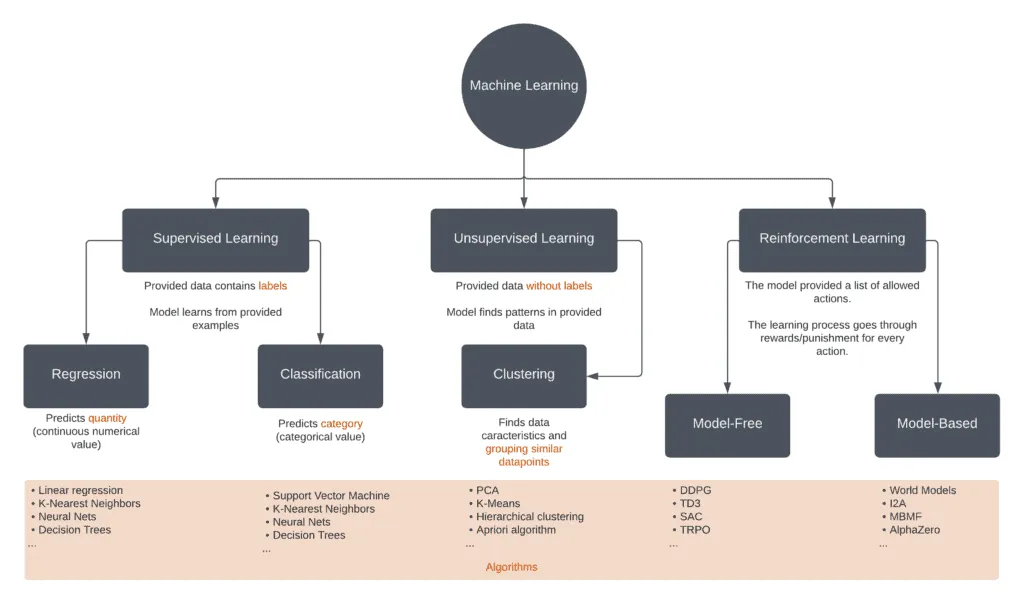
The difference between Supervised and Unsupervised learning depends on whether labels are available during training. To illustrate the difference, let’s consider the following scenario:
You are given a set of dog images and need to identify whether or not there are German Shepherd dogs in those images. If you know in advance what a German Shepherd dog looks like, solving this task would be way easier than identifying meaningful patterns in the images, figuring out similarities between dogs, and grouping the dog images into different groups.
Data mining vs. Machine Learning
Data mining is finding anomalies, patterns, and correlations within large data sets. It uses a broad range of techniques that allow you to use “mined” information to increase revenues, cut costs, improve customer relationships, reduce risks, and solve many business problems. Data mining intersects with Machine Learning. Here are some major differences:
| Data mining | Machine Learning |
|---|---|
| Allows semi-automatically extract knowledge and rules from a large amount of existing data that you can use for the decision-making process in the future | Using existing data for the creation of new algorithms that can automatically make accurate decisions and predictions in the future |
| Introduced in 1930 as knowledge discovery in databases | Introduced a couple of decades later |
| Extracts rules and patterns from the existing data | Teaches machines to learn and understand these rules |
| Uses traditional databases with unstructured data | Uses existing data from any sources and algorithms |
| Involves manual human interference | Fully automated once the model design is implemented |
| Used in cluster analysis | Used by web search engines, spam filters, fraud detection, credit scoring, image recognition, stock price predictions, etc |
| More like data research or data analysis, which can rely on Machine Learning | Self-learning and self-trained system to do the intelligent task |
| You can apply it to a limited problem set | You can use it to solve a potentially unlimited set of problems. |
Data mining frameworks for Machine Learning
Data mining is commonly used in the Machine Learning process during data management, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, training, and online updating phases. Let’s look at three major data mining frameworks you can use to get more insights from your data.
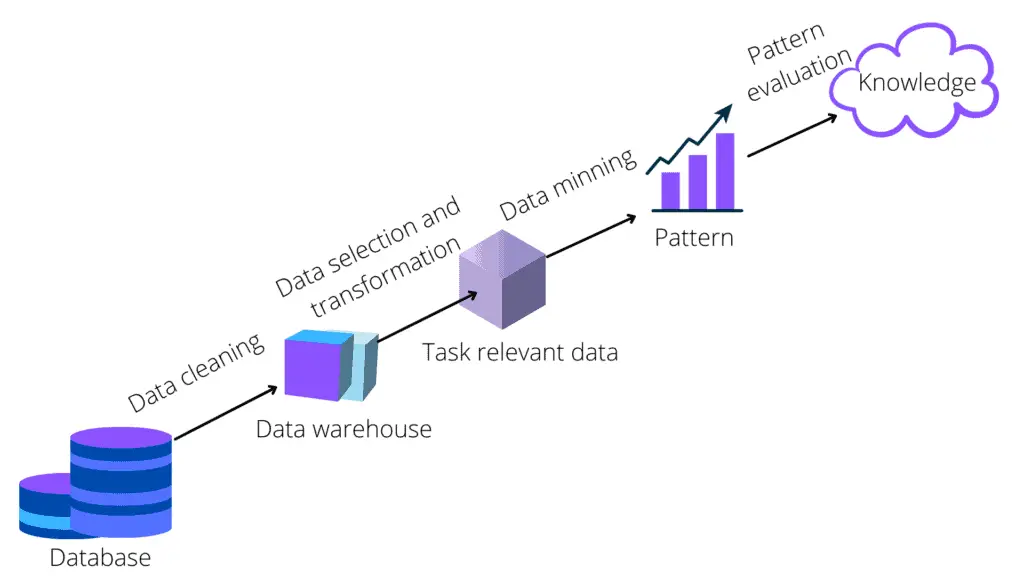
Knowledge Discovery Databases (KDD)
Knowledge Discovery in Databases (KDD) is discovering usable knowledge from a data set. This commonly used data mining technique involves data preparation and selection, data purification, adding prior knowledge into data sets, and accurately interpreting the observed results. Deep learning, learning algorithms, and training are important aspects of KDD that enable the discovery of valuable insights from large and complex datasets.
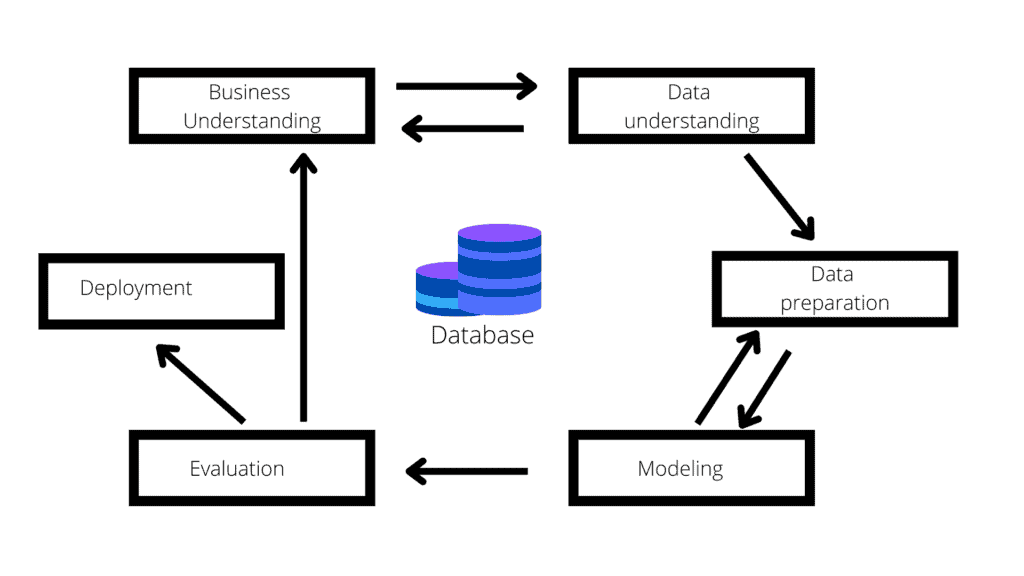
Cross Industrial Standard Process for Data Minning (CRISP-DM)
The acronym CRISP-DM is called Cross Industrial Standard Process for Data mining. The European Strategic Program on Research was created as an Information Technology initiative to develop an unbiased, domain-independent technique. It works as a series of guidelines to assist you in planning, organizing, and implementing your data science (or machine learning) project. It’s a six-phase process model that accurately depicts the data science life cycle, including training. The following diagram shows those six phases.
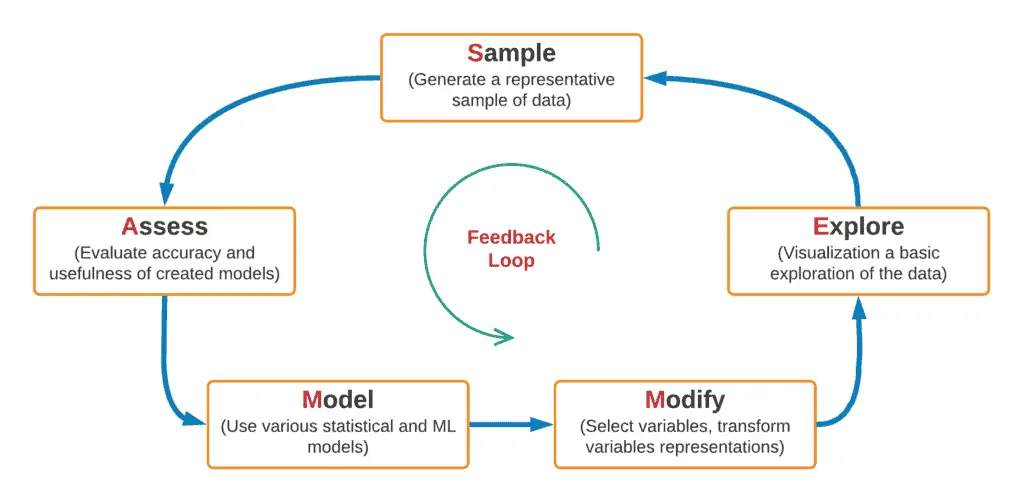
Sample, Explore, Modify, Model, and Assess (SEMMA)
The SAS Institute developed a standard data mining process called SEMMA. SEMMA stands for Sample, Explore, Modify, Model, and Assess, the five steps of the data mining process. This process involves training with various learning algorithms to improve the accuracy of the models.
- The Sample step entails choosing a subset of the appropriate volume dataset from a vast dataset for the model’s construction.
- During the Explore step, univariate and multivariate analysis is conducted to study interconnected relationships between data elements and identify gaps in the data.
- In the Modify step, lessons learned in the exploration phase from the data collected in the sample phase are derived using business logic.
- After the variables have been refined and the data has been cleaned, the Model step uses several data mining techniques to create a projected model of how this data leads to the process’s final, desired output.
- In the assessment stage, the model is evaluated for its usefulness and reliability for the studied topic.
Python in Machine Learning
Python is very popular in ML because it is a simple language to learn and develop. It allows Machine Learning engineers to validate their ideas quickly. Another reason why Python is the preferred language for ML is that it has an extensive modules library. Python modules make it easier for data scientists to conduct numerous studies that rely largely on mathematical optimization, probability, and statistics. So before taking any course on Machine learning with Python, ensure you have Python installed on your system.
The following are some of the main reasons Python is preferred for Machine Learning:
- It’s simple to use and enables quick data evaluation.
- It has a great library ecosystem. Python libraries make it easier for data scientists to conduct numerous studies because machine learning relies largely on mathematical optimization, probability, and statistics.
- Python is easy to learn.
- It is a flexible programming language. Developers can use Python and other programming languages to achieve their objectives, and the source code does not need to be recompiled.
- It is versatile. Python for machine learning can run literally on any platform, including Windows, macOS, Linux, Unix, and many, many more
- It is easy to read. When a change in the code is required, Python developers can easily implement, duplicate, or distribute it.
- Python has many supporters, and it’s good to know someone can assist you if you have an issue.
Various open-source libraries are available to make Machine Learning more realistic. These are called scientific Python libraries and are used to execute basic machine-learning tasks. Based on their usage/purpose, we can separate these libraries into data analysis and core machine learning libraries at a high level.
Data analysis packages in Python
Some of the popular data analysis packages in Python are:
- NumPy – a Python module that offers comprehensive mathematical functions, random number generators, linear algebra routines, Fourier transforms, and more
- Pandas – a fast, powerful, flexible, and easy to use open source data analysis and manipulation tool built on top of Python
- Scipy – a well-known Python module that provides algorithms for optimization, integration, interpolation, eigenvalue problems, algebraic equations, differential equations, statistics, etc
- Matplotlib – a comprehensive library for creating static, animated, and interactive visualizations in Python
- Seaborn – a Python data visualization library based on Matplotlib
Check out our article on how to build an Anaconda Python Data Science Docker Container to see what other libraries you may be interested in.
These packages give us the mathematical and scientific capabilities to execute data preprocessing, transformation, and visualization.
Core Machine Learning packages in Python
Some of the important and popular Machine Learning packages are:
- Scikit-learn – is a free software machine-learning library for the Python
- PyTorch – An open-source machine learning framework that accelerates the path from research prototyping to production deployment
- MXNet – is a fast and scalable training and inference framework with an easy-to-use, concise API for machine learning and artificial intelligence
- Keras – an open-source software library that provides a Python interface for artificial neural networks
- TensorFlow – an end-to-end open-source platform for machine learning
Scikit-learn is undoubtedly Python’s most helpful machine-learning library. Classification, regression, clustering, and dimensionality reduction are useful capabilities in the sklearn toolkit for machine learning and statistical modeling. These packages provide all the necessary machine-learning techniques and functionalities for extracting patterns from a given dataset. Keras is a neural network library, while TensorFlow is an open-source machine learning framework that you may use for various tasks. TensorFlow has high-level and low-level APIs, whereas Keras solely has high-level APIs.
AWS Machine Learning
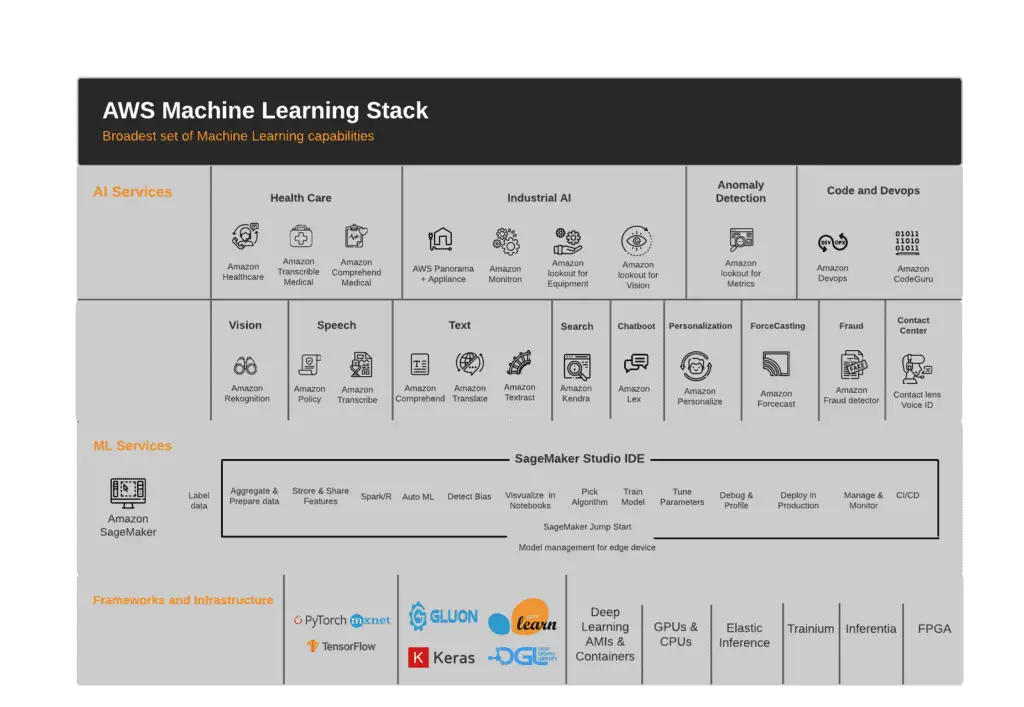
AWS Cloud provides many cloud-based services and frameworks that allow developers and engineers of all skill levels to leverage Machine Learning technologies. You can split these services into three major categories:
- Frameworks and Infrastructure – this category provides you with low-level ML frameworks and cloud infrastructure for ML tasks
- SageMaker Studio IDE – is a fully managed Machine Learning service that assists us in developing advanced machine learning models. Data scientists and developers can use SageMaker to create and train machine learning models, compare ML models’ performance, and then deploy the best working model into a production-ready hosted environment.
- AI Services – These are high-level services based on AWS ML experience that help you solve your specific business problems without any knowledge of ML. For example, you don’t have to train your ML model to use Amazon Rekognition to analyze images or videos and identify objects, people, text, scenes, and activities.
Basic Concepts of Amazon Machine Learning
The AWS cloud service has the following key Machine Learning concepts:
- Data sources store metadata about the data we’ve provided to ML service. Amazon ML analyzes your input data, computes descriptive statistics on its properties, and saves the statistics, schema, and other information as part of the Datasource object. Amazon ML then uses the Datasource to train and test an ML model and generate batch predictions.
- ML models generate predictions using the patterns extracted from the input data using mathematical models such as binary classification, multiclass classification, regression, etc.
- Evaluations – as soon as the model is ready, you can measure the quality of the ML model or compare its performance with other models based on other ML algorithms.
- Batch Predictions asynchronously generate predictions for multiple input data observations.
- Real-time Predictions synchronously generate predictions for individual data observations.
