Apriori algorithm: Easy implementation using Python
The Apriori algorithm is a well-known Machine Learning algorithm used for association rule learning. association rule learning is taking a dataset and finding relationships between items in the data. For example, if you have a dataset of grocery store items, you could use association rule learning to find items that are often purchased together. The Apriori algorithm is particularly well-suited for finding association rules in large datasets.
The Apriori algorithm identifies the frequent itemsets in the dataset and uses them to generate association rules, which provide additional recommendations based on probability (or confidence). The Apriori algorithm has been widely used in retail applications such as market basket analysis to provide additional product recommendations.
This article explains the Apriori algorithm in detail and demonstrates how to apply the Apriori algorithm (Python) on a real dataset to make recommendations.
Table of contents
Algorithm Overview
The Apriori algorithm is used on frequent item sets to generate association rules and is designed to work on the databases containing transactions. The process of generating association rules is called association rule mining or association rule learning. We can use these association rules to measure how strongly or weakly two objects from the dataset are related. Frequent itemsets are those whose support value exceeds the user-specified minimum support value.
The most common problems that this algorithm helps to solve are:
- Product recommendation
- Market basket recommendation
There are three major parts of the Apriori algorithm.
- Support
- Confidence
- Lift
Let’s take a deeper look at each one of them.
Let’s imagine we have a history of 3000 customers’ transactions in our database, and we have to calculate the Support, Confidence, and Lift to figure out how likely the customers who buy Biscuits will buy Chocolate.
Here are some numbers from our dataset:
- 3000 customers’ transactions
- 400 out of 3000 transactions contain Biscuit purchases
- 600 out of 3000 transactions contain Chocolate purchases
- 200 out of 3000 transactions described purchases when customers bought Biscuits and Chocolates together
Support
The Support of an item is defined as the percentage of transactions in which an item appears. In other words, support represents how often an item appears in a transaction. The Apriori algorithm uses a “bottom-up” approach, which starts with individual items and then finds combinations of items that appear together frequently. The Support threshold is a parameter used to determine which item sets are frequent. Itemsets with a Support value greater than or equal to the Support threshold are considered frequent.
Item support can be calculated by finding the number of transactions containing a particular item divided by the total number of transactions:
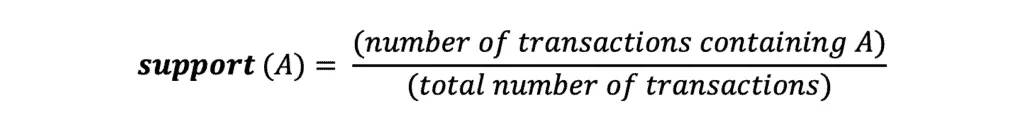
In our case, the support value for biscuits will be:
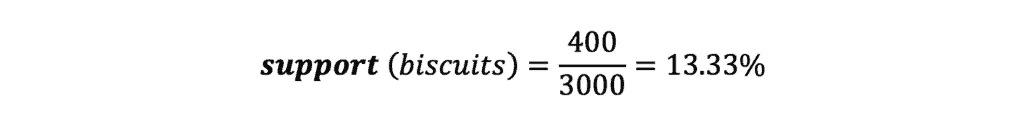
Confidence
Confidence is a statistical measure used in association rule learning that quantifies the likelihood that an association rule is correct. In other words, confidence measures the reliability of an association rule. The confidence of a rule is calculated as the ratio of the number of times the rule is found to be true to the total number of times it is checked. For example, if a rule has a confidence of 80%, this means that out of 100 times the rule is checked, it will be true 80 times.
There are several ways to increase the rule confidence, including increasing the Support or decreasing the number of exceptions. However, confidence is not a perfect measure, and it can sometimes lead to overfitting if rules with high confidence are given too much weight. Therefore, it is important to use confidence in conjunction with other measures, such as Support, to ensure that association rules are reliable.
Here’s a mathematical expression to describe how often items in transaction B appear in transactions containing A:
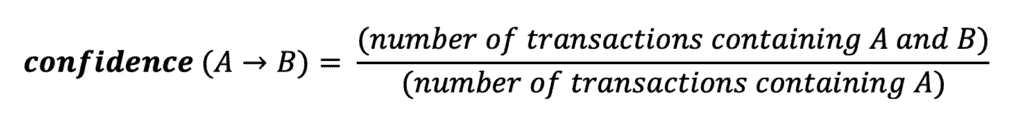
In our example, the confidence value shows the probability that customers buy Chocolate if they buy Biscuits. To calculate this value, we need to divide the number of transactions that contain Biscuits and Chocolates by the total number of transactions having Biscuits:
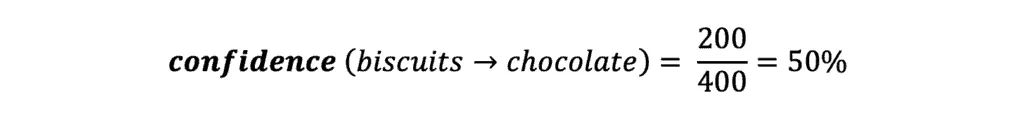
It means we are confident that 50 percent of customers who bought Biscuits will buy Chocolates too.
Lift
The Lift metric is often used to measure the strength of association between two items. Lift is simply the ratio of the observed frequency of two items being bought together to the expected frequency of them being bought together if they were independent. In other words, Lift measures how much more likely two items will be bought together than would be expected if they were unrelated. A high Lift value indicates a strong association between two items, while a low Lift value indicates a weak association. The Apriori algorithm is designed to find itemsets with a high Lift value.
Lift describes how much confident we are if B will be purchased too when the customer buys A:
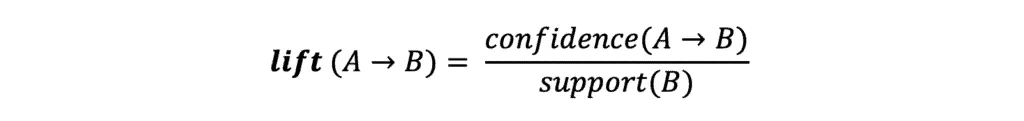
In our example, the Lift value shows the potential increase in the ratio of the sale of Chocolates when you sell Biscuits. The larger the value of the lift, the better:
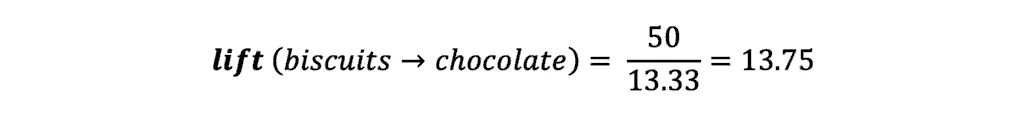
Algorithm steps
The algorithm consists of the following steps:
- Start with itemsets containing just a single item (Individual items)
- Determine the support for itemsets
- Keep the itemsets that meet the minimum support threshold and remove itemsets that do not support minimum support
- Using the itemsets kept from Step 1, generate all the possible itemset combinations.
- Repeat steps 1 and 2 until there are no more new item sets.
Let’s take a look at these steps while using a sample dataset:
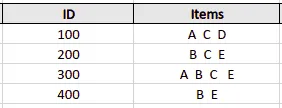
First, the algorithm will create a table containing each item set’s support count in the given dataset – the Candidate set:
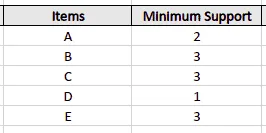
Let’s assume that we’ve set the minimum support value to 3, meaning the algorithm will drop all the items with a support value of less than three.
The algorithm will take out all the itemsets with a greater support count than the minimum support (frequent itemset) in the next step:
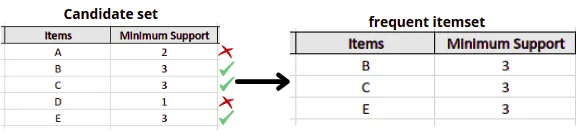
Next, the algorithm will generate the second candidate set (C2) with the help of the frequent itemset (L1) from the previous calculation. The candidate set 2 (C2) will be formed by creating the pairs of itemsets of L1. After creating new subsets, the algorithm will again find the support count from the main transaction table of datasets by calculating how often these pairs have occurred together in the given dataset.
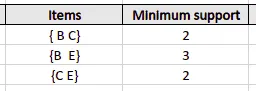
After that, the algorithm will compare the C2’s support count values with the minimum support count (3), and the itemset with less support count will be eliminated from table C2.
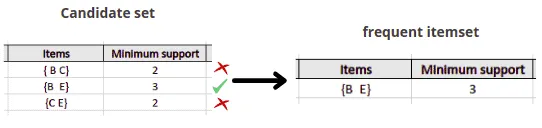
Finally, the algorithm can mine different association rules using the last frequent itemset.
Algorithm disadvantages
While the Apriori algorithm is a powerful tool for finding association rules in large datasets, it has several disadvantages that should be considered before using it:
- The algorithm requires a large amount of memory to store all possible item sets.
- Generating all possible item sets can be time-consuming, especially if the dataset is extensive.
- The algorithm can sometimes produce false positives, which means it may identify association rules that do not exist.
- The algorithm may be unable to find all the interesting associations in a dataset if the support and confidence thresholds are too high.
Despite these disadvantages, this algorithm is still widely used for finding association rules and is often applied successfully to large datasets.
Algorithm alternatives
There are several alternatives to the Apriori algorithm for finding frequent item sets in a dataset. One popular option is the Eclat algorithm, which uses an efficient depth-first search strategy to find itemsets that are close together in the data. Another common alternative is the FP-growth algorithm, which uses a compression technique to represent the data more compactly. This can be used to speed up the search for frequent itemsets.
Finally, the frequent pattern mining (FPM) method is a general approach that can be used with various algorithms, including Apriori. FPM first converts the data into a lattice structure, which is then mined for frequent itemsets using one of several algorithms. Each method has advantages and disadvantages, and there is no consensus on the best. Ultimately, the choice of algorithm will depend on the specific application and dataset.
Using the Apriori algorithm in Python
We will use the market basket optimization dataset (you can download the dataset here).
Before starting to use the algorithm in Python, we need to install the required modules by running the following commands in the cell of the Jupyter notebook:
pip install pandas
pip install numpy
pip install plotly
pip install networkx
pip install matplotlibExploring dataset
First, let’s import the dataset and get familiar with it. We will use the Pandas DataFrame to store and manipulate our dataset:
# importing module
import pandas as pd
# dataset
data = pd.read_csv("Market_Basket_Optimisation.csv")
# printing the shape of the dataset
data.shapeOutput:
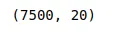
The output shows that our dataset contains 7500 rows/observations and 20 columns/attributes. We can print out the dataset’s first few rows and columns to see what kind of data our dataset contains.
# printing the heading
data.head()Output:
Visualizing the dataset
As you can see, there are a lot of null values in our dataset, and it isn’t easy to figure out which item has been purchased more. We can iterate through our data and store each item in a separate NumPy array.
Let’s print out the top 10 most frequent items from the dataset.
# importing module
import numpy as np
# Gather All Items of Each Transactions into Numpy Array
transaction = []
for i in range(0, data.shape[0]):
for j in range(0, data.shape[1]):
transaction.append(data.values[i,j])
# converting to numpy array
transaction = np.array(transaction)
# Transform Them a Pandas DataFrame
df = pd.DataFrame(transaction, columns=["items"])
# Put 1 to Each Item For Making Countable Table, to be able to perform Group By
df["incident_count"] = 1
# Delete NaN Items from Dataset
indexNames = df[df['items'] == "nan" ].index
df.drop(indexNames , inplace=True)
# Making a New Appropriate Pandas DataFrame for Visualizations
df_table = df.groupby("items").sum().sort_values("incident_count", ascending=False).reset_index()
# Initial Visualizations
df_table.head(10).style.background_gradient(cmap='Greens')Output:
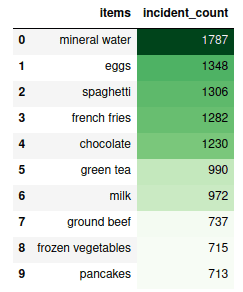
The output shows that mineral water has been purchased more frequently than other products.
A treemapping is a method for displaying hierarchical data using nested figures, usually rectangles. We can use a treemap to visualize all the items from our dataset more interactive.
# importing required module
import plotly.express as px
# to have a same origin
df_table["all"] = "all"
# creating tree map using plotly
fig = px.treemap(df_table.head(30), path=['all', "items"], values='incident_count',
color=df_table["incident_count"].head(30), hover_data=['items'],
color_continuous_scale='Greens',
)
# ploting the treemap
fig.show()Output:
Data pre-processing
Before getting the most frequent itemsets, we need to transform our dataset into a True – False matrix where rows are transactions and columns are products.
Possible cell values are:
True– the transaction contains the itemFalse– transaction does not contain the item
# importing the required module
from mlxtend.preprocessing import TransactionEncoder
# initializing the transactionEncoder
te = TransactionEncoder()
te_ary = te.fit(transaction).transform(transaction)
dataset = pd.DataFrame(te_ary, columns=te.columns_)
# dataset after encoded
datasetOutput:
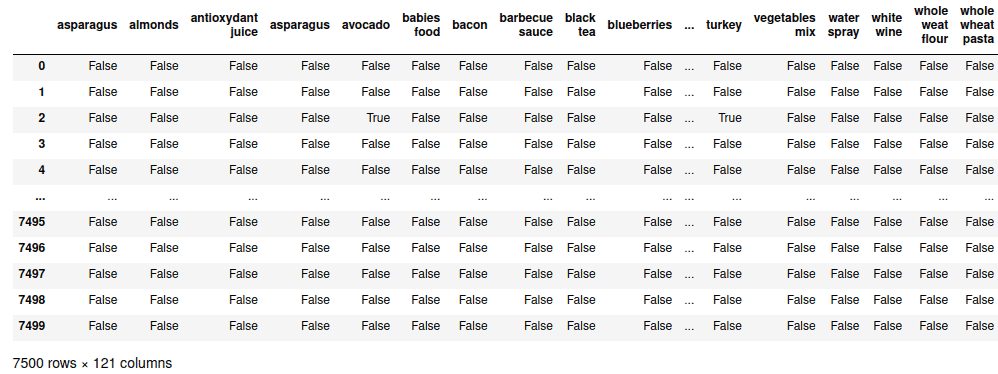
We have 121 columns/features at the moment. Extracting the most frequent itemsets from 121 features would be compelling. So, we will start with the Top 50 items.
# select top 50 items
first50 = df_table["items"].head(50).values
# Extract Top50
dataset = dataset.loc[:,first50]
# shape of the dataset
dataset.shapeOutput:
Notice that the number of columns is now 50.
Using Apriori algorithm
Now we can use mlxtend module that contains the Apriori algorithm implementation to get insights from our data.
# importing the required module
from mlxtend.frequent_patterns import apriori, association_rules
# Extracting the most frequest itemsets via Mlxtend.
# The length column has been added to increase ease of filtering.
frequent_itemsets = apriori(dataset, min_support=0.01, use_colnames=True)
frequent_itemsets['length'] = frequent_itemsets['itemsets'].apply(lambda x: len(x))
# printing the frequent itemset
frequent_itemsetsOutput:
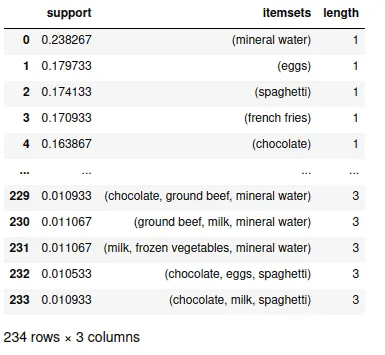
The output shows that mineral water is our dataset’s most frequently occurring item. We can explore the frequent item more to get the inside. For example, we can print out all items with a length of 2, and the minimum support is more than 0.05.
# printing the frequntly items
frequent_itemsets[ (frequent_itemsets['length'] == 2) &
(frequent_itemsets['support'] >= 0.05) ]Output:
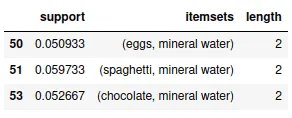
The output shows that the eggs and mineral water combination are the most frequently occurring items when the length of the itemset is two.
Similarly, we can find the most frequently occurring items when the itemset length is 3:
# printing the frequntly items with length 3
frequent_itemsets[ (frequent_itemsets['length'] == 3) ].head(3)Output:
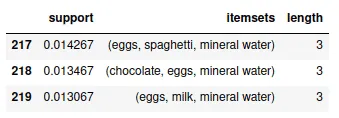
The output shows that the most frequent items with a length of three are eggs, spaghetti, and mineral water.
Mining association rules
We know that the association rules are “if-else” statements. The IF component of an association rule is known as the antecedent. The THEN component is known as the consequent. The antecedent and the consequent are disjoint; they have no items in common.
So, let’s create antecedents and consequents:
# We set our metric as "Lift" to define whether antecedents & consequents are dependent our not
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1.2)
rules["antecedents_length"] = rules["antecedents"].apply(lambda x: len(x))
rules["consequents_length"] = rules["consequents"].apply(lambda x: len(x))
rules.sort_values("lift",ascending=False)Output:
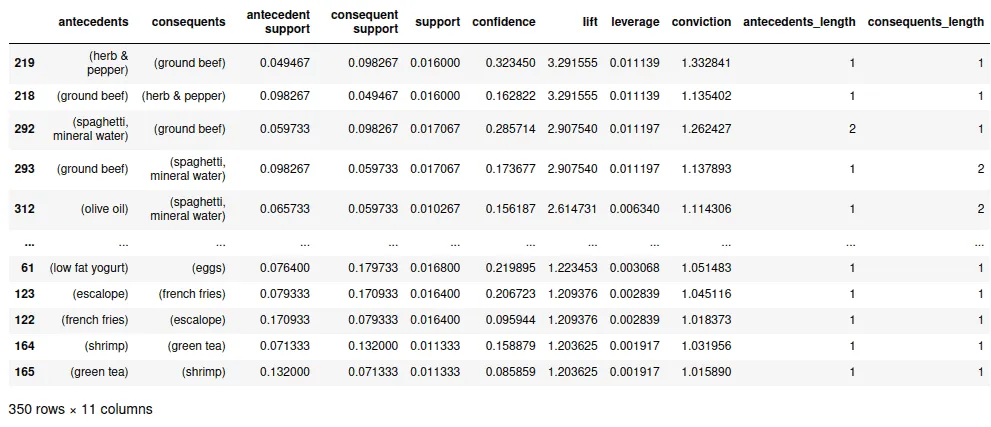
The output above shows the values of various supporting components. To get more insights from the data, let’s sort the data by the confidence value:
# Sort values based on confidence
rules.sort_values("confidence",ascending=False)Output:
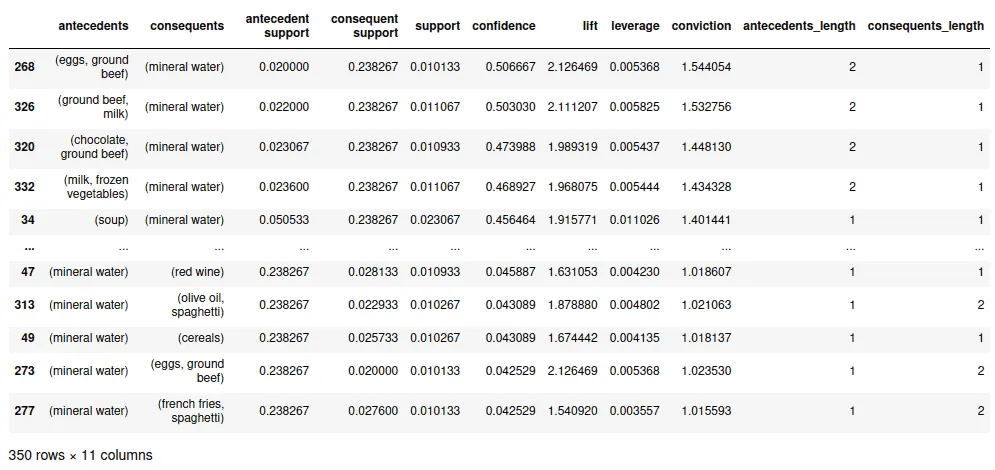
This table shows the relationship between different items and the likelihood of a customer buying those items together. For example, according to the table above, the customers who purchased eggs and ground beef are expected to buy mineral water with a likelihood of 50% (confidence).
FAQ
What does the Apriori algorithm do?
Is the Apriori algorithm still used?
What are the two steps of the Apriori algorithm?
Summary
The Apriori algorithm is a powerful tool for finding relationships between items in a dataset. In this article, we have covered the basics of the algorithm and shown how to implement it in Python. We hope you find this information useful and can now use the Apriori algorithm to discover valuable insights from your data sets.
