Popular Boosting Algorithms in Machine Learning
Boosting is a Machine Learning (ML) technique used to create more accurate models than traditional ML models. It works by combining multiple weak ML models, such as Decision Trees, to create a strong model. The individual models are created using a training set, and the boosting algorithm then determines how to combine the best. The resulting model is more accurate than any individual model and is often better at making predictions on new data. In this article, we will discuss popular Boosting algorithms in Machine Learning. We will also cover the advantages and applications of Boosting in Machine Learning.
Table of contents
We assume that you have basic knowledge of Machine learning and some Supervised Machine Learning algorithms. You can read about supervised machine learning algorithms in the article Overview of Supervised Machine Learning algorithms. Also, ensure that you have a basic understanding of Decision Trees, as most boosting algorithms combine different decision trees to make a better model.
What is Boosting in Machine learning?
As we discussed, Boosting is a Machine Learning technique used to improve the accuracy of predictive models. It combines multiple weaker models, such as decision trees, to create a more robust model. The individual models are trained sequentially, compensating for the previous model’s errors. The final predictions are made by combining the predictions of all the individual models. Boosting can be used for regression and classification tasks and is a powerful tool for dealing with nonlinear data. It is also relatively resistant to overfitting, meaning it can often achieve high levels of accuracy without sacrificing generalizability. Boosting is a popular choice for many practical ML applications.
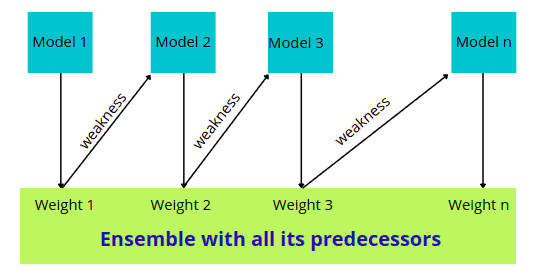
In Boosting, a random sample of data is selected, fitted with a model, and then trained sequentially – each model tries to compensate for the weaknesses of its predecessor. With each iteration, the weak rules from each classifier are combined to form one strict prediction rule.
Weak learner and Strong learner in Boosting
It is common to describe ensemble learning techniques as weak and strong learners. A weak learner is a model that performs slightly better than random guessing. The most commonly used type of weak learning model is the decision tree. This is because the tree’s depth can control the tree’s weakness during construction.
While Strong learners have higher prediction accuracy, Boosting converts a system of weak learners into a single strong learning system. A strong learner is a model that tries to overcome the weakness and errors of the weak model to give better predictions.
How the Boosting algorithms work
As we know, the basic principle behind the working of the Boosting algorithm is to generate multiple weak learners and combine their predictions to form one strict rule. These weak rules are generated by applying base Machine Learning algorithms on different distributions of the data set. These algorithms generate weak rules for each iteration. After multiple iterations, the weak learners are combined to form a strong learner to predict a more accurate outcome.
For example, the figure below shows how weak learners are combined to make strong learners.
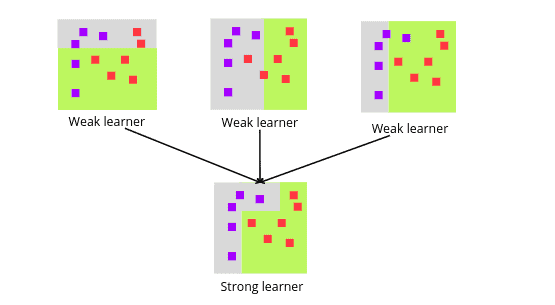
The three most important steps of Boosting algorithm are:
- The weak learner considers all the distributions and then assigns equal weight to each observation.
- If the error is caused by prediction from the first weak learning model, then more attention is given to the observations’ prediction error to overcome it in the next weak learner model.
- Iterate through the second step until the base learning algorithm reaches its limit or achieves desirable accuracy.
Why is Boosting so popular?
Boosting algorithms are getting more and more popular and powerful. The following are some of the critical points for their popularity.
- Boosting has easy-to-understand and easy-to-interpret algorithms that learn from their mistakes. These algorithms don’t require data preprocessing, and they have built-in routines to handle missing data. In addition, most languages have built-in libraries to implement boosting algorithms with many parameters that can fine-tune performance.
- Bias is the presence of uncertainty or inaccuracy in machine learning results. Boosting algorithms combine multiple weak learners in a sequential method, which iteratively improves observations. This approach helps reduce the high bias common in machine learning models.
- Boosting algorithms prioritize features that increase predictive accuracy during training. They can help to reduce data attributes and handle large datasets efficiently.
Real-life applications of Boosting algorithms
The following are some of the real-life applications of Boosting algorithms.
- Boosting is used to lower errors in medical data predictions, such as predicting cardiovascular risk factors and cancer patient survival rates.
- Gradient-boosted regression trees are used in search engines for page rankings, while the Viola-Jones boosting algorithm is used for image retrieval.
- Boosting is used with deep learning models to automate critical tasks, including fraud detection, pricing analysis, etc.
- The Catboost algorithm is used for search, recommendation systems, personal assistants, self-driving cars, weather prediction, and other tasks at Yandex and other companies.
Popular Boosting Machine learning algorithms
Boosting algorithms have been around for years, yet only recently have they become mainstream in the Machine Learning community. Boosting algorithms grants superpowers to Machine Learning models to improve their prediction accuracy – one of the primary reasons for the rise in the adoption of boosting algorithms in machine learning competitions.
This section will quickly go through some popular boosting algorithms, implement them on a sample dataset, and compare their running time.
You can access the sample dataset, which is about the salary of adults, and read about it from this link. Here, we will use this dataset to compare the accuracy and running time of the above-given Boosting algorithms. But before comparing, let us first import the dataset, preprocess it, and split it into testing and training datasets.
# importing the pandas module
import pandas as pd
# importing the dataset
dataset = pd.read_csv('adult.data', header=None)
# printing rows
dataset.head()Output:
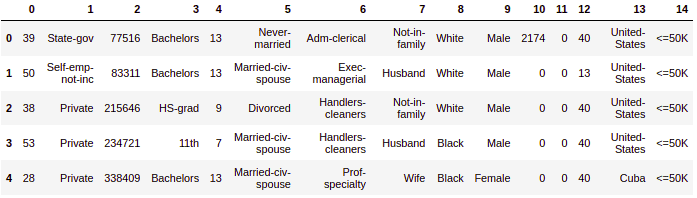
As you can see, most columns are object types, so we need to convert them into integers or float to train some of the boosting models.
# importing the module
from sklearn import preprocessing
# label encoding the dataset
dataset = dataset.apply(preprocessing.LabelEncoder().fit_transform)The next step is to split the dataset into the testing and training parts so that after training the models, we can use the testing dataset to evaluate the performance.
#Training and testing data
from sklearn.model_selection import train_test_split
# storing the input values in the X variable
x_data = dataset.iloc[:,[0,13]].values
# storing all the ouputs in y variable
y_data = dataset.iloc[:,14].values
# splitting dataset
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size = 0.3, random_state = 0)We assigned 70% of the training data to the training and the remaining 30% to the testing data.
AdaBoost algorithm
The AdaBoost algorithm, short for the Adaptive Boosting algorithm, is a boosting technique used as an ensemble method in Supervised Machine Learning. It is Adaptive Boosting as the weights are re-assigned to each instance, with higher weights assigned to incorrectly classified instances.
The most common algorithm used with AdaBoost is decision trees with one level, which means Decision trees with only one split. These trees are also called Decision Stumps.
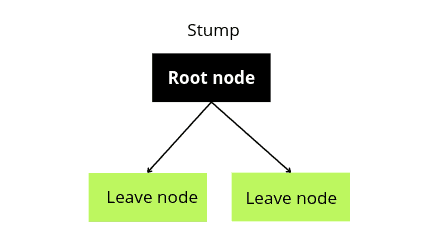
Adaboosting algorithms make such stump trees ( weak learners) and then combine their results to create a predictive model ( strong learners). You can learn more about how the Adaboost algorithm works from the article implementation of the AdaBoost algorithm using Python.
Let us import the module and train the model on the training dataset.
# importing the adaptive boosting algorithm
from sklearn.ensemble import AdaBoostClassifier
# importing date and time modue
from datetime import datetime as dt
# starting the time
start = dt.now()
# starting the adaptive boosting algorithm
Ada_clf = AdaBoostClassifier(n_estimators=100,random_state=1)
# training the mode
Ada_clf.fit(x_train, y_train)
# Ending the time after training
running_secs = (dt.now() - start)
# printing the training time
print("The training time is : ", running_secs)Output:

The output shows what it takes to train the AdaBoost model is 0.516431 seconds.
Now let us also use the testing data to find the model’s accuracy.
# testing the adaptive boosting model
ada_pred = Ada_clf.predict(x_test)
# importing accuracy score
from sklearn.metrics import accuracy_score
# finding the accuracy
accuracy_score(y_test,ada_pred)Output:
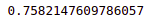
The output shows that the model could accurately classify 75% of the testing data.
Gradient Boosting algorithm
The Gradient Boosting Algorithm is known as Gradient Tree Boosting, Stochastic Gradient Boosting, or GBM. This algorithm allows us to assemble an ultimate training model from simple prediction models, typically decision trees. You can use it for predicting both regression and classification datasets. When used as a regressor, the cost function is Mean Square Error (MSE), and when used as a classifier, the cost function is Log loss.
A Gradient Boost Algorithm starts training by creating a single leaf from the output dataset values. This leaf is the initial guess for the output values of the dataset. The algorithm builds new Decision Trees during its execution based on the errors’ values calculated from previous tree outputs. For example, in the case of continuous target variables, the initial guess of the Gradient Boost Algorithm will be the mean of the target (output) variable. In the case of a classification problem, the initial guess is the log(odd). You can read more about the working and implementation of the Gradient Boost algorithm in the article implementation of Gradient Boosting algorithm on regression and classification problems.
Here we will train the Gradient Boost model and calculate the accuracy and training time. Let us first introduce the model and calculate the training time.
# importing the required module
from sklearn.ensemble import GradientBoostingClassifier
# starting the time
start = dt.now()
# training with default values
GB_classifier=GradientBoostingClassifier(n_estimators = 100)
# Training the mode
GB_classifier.fit(x_train,y_train)
# Ending the time after training
running_secs = (dt.now() - start)
# printing the training time
print("The training time is : ", running_secs)Output:

Notice that the Gradient Boosting algorithm takes 0.473401 seconds to train the model. Let us also calculate the accuracy of the model.
# testing the adaptive boosting model
gbm_pred = GB_classifier.predict(x_test)
# finding the accuracy
accuracy_score(y_test,gbm_pred)Output:
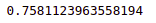
The output shows that the model could correctly classify 75% of the testing dataset.
XGBoost algorithm
XGBoost (Extreme Gradient Boosting) is a scalable and highly accurate implementation of gradient boosting that pushes the limits of computing power for boosted tree algorithms. You can use it for both classification and regression datasets. XGBoost algorithm was developed as a research project at the University of Washington and presented the research paper at the SIGKDD Conference in 2016.
The XGBoost algorithm takes some critical parameters. You can learn more about these important and the working of XGBoost from the article implementation of the XGBoost algorithm using Python.
Here we will use the same training dataset to calculate the training time and accuracy of the model.
# importing xgboost
import xgboost as xgb
# starting the time
start = dt.now()
# Default parameters
xg_clf = xgb.XGBClassifier(iterations=100)
# training the model
xg_clf.fit(x_train,y_train)
# Ending the time after training
running_secs = (dt.now() - start)
# printing the training time
print("The training time is : ", running_secs)Output:
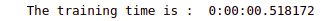
The output shows that the model took 0.518172 seconds to train the model. Let us also find out the accuracy of the model.
# testing the adaptive boosting model
xg_pred = xg_clf.predict(x_test)
# finding the accuracy
accuracy_score(y_test,xg_pred)Output:
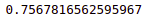
XGBoost model was able to classify 75% of the testing data correctly.
LighGBM
LightGBM is a distributed and efficient gradient-boosting framework that uses tree-based learning. It’s histogram-based and places continuous values into discrete bins, which leads to faster training and more efficient memory usage. It is also used for both classification and regression problems. One of the critical features of LighGBM is that it can handle the missing values automatically.
It was developed by Microsoft company and was made publically available in 2016. It works similarly to other boosting algorithms but with some advanced features, making it one of the fasted boosting algorithms.
Here we will use the same training dataset to calculate the training time and accuracy of the model.
# importing the lightgbm model
import lightgbm as lgbm
# starting the time
start = dt.now()
# Default parameters
lgbm_clf = lgbm.LGBMClassifier(iterations = 100)
# training the model
lgbm_clf.fit(x_train,y_train)
# Ending the time after training
running_secs = (dt.now() - start)
# printing the training time
print("The training time is : ", running_secs)Output:
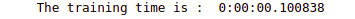
Notice that the training time of LightGBM is significantly less than other boosting algorithms mentioned above. Let us also calculate the accuracy as well.
# testing the adaptive boosting model
lgbm_pred = lgbm_clf.predict(x_test)
# finding the accuracy
accuracy_score(y_test,lgbm_pred)Output:
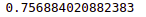
Again we get 75% accuracy for the LighGBM model as well.
CatBoost
CatBoost (Categorical Boosting) is an open-source software library developed by Yandex, which was released in 2017. It is also used for regression and classification problems. It also automatically converts string/object values to categorical values, apart from handling null values.
This algorithm is designed to work with categorical features and works similarly to Gradient and XGboost algorithms. Still, it has some advanced features which make it more reliable, fast, and accurate.
Let us calculate the training time and accuracy of the CatBoost algorithm on the training dataset.
# importing the classifier
from catboost import CatBoostClassifier
# starting the time
start = dt.now()
# Default parameters
cat_clf = CatBoostClassifier(iterations=100)
# training the model
cat_clf.fit(x_train,y_train)
# Ending the time after training
running_secs = (dt.now() - start)
# printing the training time
print("The training time is : ", running_secs)Output:
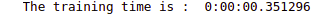
Notice that the training time of the CatBoost model is 0.351296 seconds. Let us also calculate the accuracy of the model.
# testing the adaptive boosting model
cat_pred = cat_clf.predict(x_test)
# finding the accuracy
accuracy_score(y_test,cat_pred)Output:
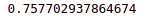
The CatBoost model also gives an accuracy score of 75%
Comparing the training time of boosting algorithms
As we saw that the accuracies of each of the boosting models were nearly the same, the only difference was in the training time. But we cannot generalize based on the observations above and say one boosting algorithm is better than the other. Because the training time and accuracy usually depend on the data we are considering. For example, one model can perform well on one dataset but not on the other set. So, the accuracy and training time results are limited to only the given dataset.
The following is the order of training time for boosting algorithms on our dataset.

Summary
In this article, we discussed Booting in machine learning and its importance. Boosting is an ensemble learning method combining weak learners into strong learners to minimize training errors. Also, we covered some of the popular Boosting algorithms and compared them based on their training time.
